3. Virtual Private Routed Network Service
3.1. VPRN Service Overview
RFC 2547b is an extension to the original RFC 2547, BGP/MPLS VPNs, which details a method of distributing routing information using BGP and MPLS forwarding data to provide a Layer 3 Virtual Private Network (VPN) service to end customers.
Each Virtual Private Routed Network (VPRN) consists of a set of customer sites connected to one or more PE routers. Each associated PE router maintains a separate IP forwarding table for each VPRN. Additionally, the PE routers exchange the routing information configured or learned from all customer sites via MP-BGP peering. Each route exchanged via the MP-BGP protocol includes a Route Distinguisher (RD), which identifies the VPRN association and handles the possibility of IP address overlap.
The service provider uses BGP to exchange the routes of a particular VPN among the PE routers that are attached to that VPN. This is done in a way which ensures that routes from different VPNs remain distinct and separate, even if two VPNs have an overlapping address space. The PE routers peer with locally connected CE routers and exchange routes with other PE routers in order to provide end-to-end connectivity between CEs belonging to a given VPN. Since the CE routers do not peer with each other there is no overlay visible to the CEs.
When BGP distributes a VPN route it also distributes an MPLS label for that route. On an SR series router, the method of allocating a label to a VPN route depends on the VPRN label mode and the configuration of the VRF export policy. SR series routers support three label allocation methods: label per VRF, label per next hop, and label per prefix.
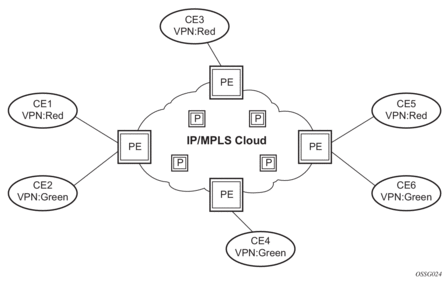
Before a customer data packet travels across the service provider's backbone, it is encapsulated with the MPLS label that corresponds, in the customer's VPN, to the route which best matches the packet's destination address. The MPLS packet is further encapsulated with one or additional MPLS labels or GRE tunnel header so that it gets tunneled across the backbone to the proper PE router. Each route exchanged by the MP-BGP protocol includes a route distinguisher (RD), which identifies the VPRN association. Thus the backbone core routers do not need to know the VPN routes. Figure 9 displays a VPRN network diagram example.
Figure 9: Virtual Private Routed Network
3.1.1. Routing Prerequisites
RFC4364 requires the following features:
- multi-protocol extensions to BGP
- extended BGP community support
- BGP capability negotiation
Tunneling protocol options are as follows:
- Label Distribution Protocol (LDP)
- MPLS RSVP-TE tunnels
- Generic Router Encapsulation (GRE) tunnels
- BGP route tunnel (RFC3107)
3.1.2. Core MP-BGP Support
BGP is used with BGP extensions mentioned in Routing Prerequisites to distribute VPRN routing information across the service provider’s network.
BGP was initially designed to distribute IPv4 routing information. Therefore, multi-protocol extensions and the use of a VPN-IP address were created to extend BGP’s ability to carry overlapping routing information. A VPN-IPv4 address is a 12-byte value consisting of the 8-byte route distinguisher (RD) and the 4-byte IPv4 IP address prefix. A VPN-IPv6 address is a 24-byte value consisting of the 8-byte RD and 16-byte IPv6 address prefix. Service providers typically assign one or a small number of RDs per VPN service network-wide.
3.1.3. Route Distinguishers
The route distinguisher (RD) is an 8-byte value consisting of two major fields, the Type field and Value field. The Type field determines how the Value field should be interpreted. The 7750 SR and 7950 XRS implementation supports the three (3) Type values as defined in the standard.
Figure 10: Route Distinguisher

The three Type values are:
- Type 0: Value Field — Administrator subfield (2 bytes)Assigned number subfield (4 bytes)
The administrator field must contain an AS number (using private AS numbers is discouraged). The Assigned field contains a number assigned by the service provider.
- Type 1: Value Field — Administrator subfield (4 bytes)Assigned number subfield (2 bytes)
The administrator field must contain an IP address (using private IP address space is discouraged). The Assigned field contains a number assigned by the service provider.
- Type 2: Value Field — Administrator subfield (4 bytes)Assigned number subfield (2 bytes)
The administrator field must contain a 4-byte AS number (using private AS numbers is discouraged). The Assigned field contains a number assigned by the service provider.
3.1.3.1. eiBGP Load Balancing
eiBGP load balancing allows a route to have multiple nexthops of different types, using both IPv4 nexthops and MPLS LSPs simultaneously.
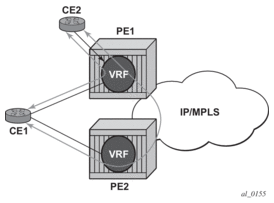
Figure 11 displays a basic topology that could use eiBGP load balancing. In this topology CE1 is dual homed and thus reachable by two separate PE routers. CE 2 (a site in the same VPRN) is also attached to PE1. With eiBGP load balancing, PE1 will utilize its own local IPv4 nexthop as well as the route advertised by MP-BGP, by PE2.
Figure 11: Basic eiBGP Topology
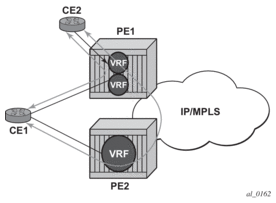
Another example displayed in Figure 12 shows an extra net VPRN (VRF). The traffic ingressing the PE that should be load balanced is part of a second VPRN and the route over which the load balancing is to occur is part of a separate VPRN instance and are leaked into the second VPRN by route policies.
Here, both routes can have a source protocol of VPN-IPv4 but one will still have an IPv4 nexthop and the other can have a VPN-IPv4 nexthop pointing out a network interface. Traffic will still be load balanced (if eiBGP is enabled) as if only a single VRF was involved.
Figure 12: Extranet Load Balancing
Traffic will be load balanced across both the IPv4 and VPN-IPv4 next hops. This helps to use all available bandwidth to reach a dual-homed VPRN.
3.1.4. Route Reflector
The use of Route Reflectors is supported in the service provider core. Multiple sets of route reflectors can be used for different types of BGP routes, including IPv4 and VPN-IPv4 as well as multicast and IPv6 (multicast and IPv6 apply to the 7750 SR only).
3.1.5. CE to PE Route Exchange
Routing information between the Customer Edge (CE) and Provider Edge (PE) can be exchanged by the following methods:
- Static Routes
- E-BGP
- RIP
- OSPF
- OSPF3
Each protocol provides controls to limit the number of routes learned from each CE router.
3.1.5.1. Route Redistribution
Routing information learned from the CE-to-PE routing protocols and configured static routes should be injected in the associated local VPN routing/forwarding (VRF). In the case of dynamic routing protocols, there may be protocol specific route policies that modify or reject certain routes before they are injected into the local VRF.
Route redistribution from the local VRF to CE-to-PE routing protocols is to be controlled via the route policies in each routing protocol instance, in the same manner that is used by the base router instance.
The advertisement or redistribution of routing information from the local VRF to or from the MP-BGP instance is specified per VRF and is controlled by VRF route target associations or by VRF route policies.
VPN-IP routes imported into a VPRN, have the protocol type bgp-vpn to denote that it is an VPRN route. This can be used within the route policy match criteria.
3.1.5.2. CPE Connectivity Check
Static routes are used within many IES services and VPRN services. Unlike dynamic routing protocols, there is no way to change the state of routes based on availability information for the associated CPE. CPE connectivity check adds flexibility so that unavailable destinations will be removed from the VPRN routing tables dynamically and minimize wasted bandwidth. Figure 13 shows a setup with a directly connected IP target and Figure 14 shows a setup with multiple hops to an IP target.
Figure 13: Directly Connected IP Target
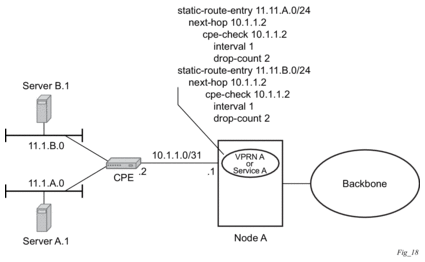
Figure 14: Multiple Hops to IP Target
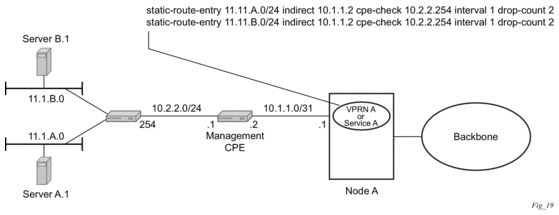
The availability of the far-end static route is monitored through periodic polling. The polling period is configured. If the poll fails a specified number of sequential polls, the static route is marked as inactive.
Either ICMP ping or unicast ARP mechanism can be used to test the connectivity. ICMP ping is preferred.
If the connectivity check fails and the static route is deactivated, the router will continue to send polls and re-activate any routes that are restored.
3.1.6. Constrained Route Distribution (RT Constraint)
3.1.6.1. Constrained VPN Route Distribution Based on Route Targets
Constrained Route Distribution (or RT Constraint) is a mechanism that allows a router to advertise Route Target membership information to its BGP peers to indicate interest in receiving only VPN routes tagged with specific Route Target extended communities. Upon receiving this information, peers restrict the advertised VPN routes to only those requested, minimizing control plane load in terms of protocol traffic and possibly also RIB memory.
The Route Target membership information is carried using MP-BGP, using an AFI value of 1 and SAFI value of 132. In order for two routers to exchange RT membership NLRI they must advertise the corresponding AFI/SAFI to each other during capability negotiation. The use of MP-BGP means RT membership NLRI are propagated, loop-free, within an AS and between ASes using well-known BGP route selection and advertisement rules.
ORF can also be used for RT-based route filtering, but ORF messages have a limited scope of distribution (to direct peers) and therefore do not automatically create pruned inter-cluster and inter-AS route distribution trees.
3.1.6.2. Configuring the Route Target Address Family
RT Constraint is supported only by the base router BGP instance. When the family command at the BGP router group or neighbor CLI context includes the route-target keyword, the RT Constraint capability is negotiated with the associated set of EBGP and IBGP peers.
ORF is mutually exclusive with RT Constraint on a particular BGP session. The CLI will not attempt to block this configuration, but if both capabilities are enabled on a session, the ORF capability will not be included in the OPEN message sent to the peer.
3.1.6.3. Originating RT Constraint Routes
When the base router has one or more RTC peers (BGP peers with which the RT Constraint capability has been successfully negotiated), one RTC route is created for each RT extended community imported into a locally-configured L2 VPN or L3 VPN service. These imported route targets are configured in the following contexts:
- config>service>vprn
- config>service>vprn>mvpn
By default, these RTC routes are automatically advertised to all RTC peers, without the need for an export policy to explicitly “accept” them. Each RTC route has a prefix, a prefix length and path attributes. The prefix value is the concatenation of the origin AS (a 4 byte value representing the 2- or 4-octet AS of the originating router, as configured using the config>router>autonomous-system command) and 0 or 16-64 bits of a route target extended community encoded in one of the following formats: 2-octet AS specific extended community, IPv4 address specific extended community, or 4-octet AS specific extended community.
A router may be configured to send the default RTC route to any RTC peer. This is done using the new default-route-target group/neighbor CLI command. The default RTC route is a special type of RTC route that has zero prefix length. Sending the default RTC route to a peer conveys a request to receive all VPN routes (regardless of route target extended community) from that peer. The default RTC route is typically advertised by a route reflector to its clients. The advertisement of the default RTC route to a peer does not suppress other more specific RTC routes from being sent to that peer.
3.1.6.4. Receiving and Re-Advertising RT Constraint Routes
All received RTC routes that are deemed valid are stored in the RIB-IN. An RTC route is considered invalid and treated as withdrawn, if any of the following applies:
- The prefix length is 1-31.
- The prefix length is 33-47.
- The prefix length is 48-96 and the 16 most-significant bits are not 0x0002, 0x0102 or 0x0202.
If multiple RTC routes are received for the same prefix value then standard BGP best path selection procedures are used to determine the best of these routes.
The best RTC route per prefix is re-advertised to RTC peers based on the following rules:
- The best path for a default RTC route (prefix-length 0, origin AS only with prefix-length 32, or origin AS plus 16 bits of an RT type with prefix-length 48) is never propagated to another peer.
- A PE with only IBGP RTC peers that is neither a route reflector or an ASBR does not re-advertise the best RTC route to any RTC peer due to standard IBGP split horizon rules.
- A route reflector that receives its best RTC route for a prefix from a client peer re-advertises that route (subject to export policies) to all of its client and non-client IBGP peers (including the originator), per standard RR operation. When the route is re-advertised to client peers, the RR (i) sets the ORIGINATOR_ID to its own router ID and (ii) modifies the NEXT_HOP to be its local address for the sessions (for example, system IP).
- A route reflector that receives its best RTC route for a prefix from a non-client peer re-advertises that route (subject to export policies) to all of its client peers, per standard RR operation. If the RR has a non-best path for the prefix from any of its clients, it advertises the best of the client-advertised paths to all non-client peers.
- An ASBR that is neither a PE nor a route reflector that receives its best RTC route for a prefix from an IBGP peer re-advertises that route (subject to export policies) to its EBGP peers. It modifies the NEXT_HOP and AS_PATH of the re-advertised route per standard BGP rules. No aggregation of RTC routes is supported.
- An ASBR that is neither a PE nor a route reflector that receives its best RTC route for a prefix from an EBGP peer re-advertises that route (subject to export policies) to its EBGP and IBGP peers. When re-advertised routes are sent to EBGP peers, the ASBR modifies the NEXT_HOP and AS_PATH per standard BGP rules. No aggregation of RTC routes is supported.
| Note: These advertisement rules do not handle hierarchical RR topologies properly. This is a limitation of the current RT constraint standard. |
3.1.6.5. Using RT Constraint Routes
In general (ignoring IBGP-to-IBGP rules, Add-Path, Best-external, etc.), the best VPN route for every prefix/NLRI in the RIB is sent to every peer supporting the VPN address family, but export policies may be used to prevent some prefix/NLRI from being advertised to specific peers. These export policies may be configured statically or created dynamically based on use of ORF or RT constraint with a peer. ORF and RT Constraint are mutually exclusive on a session.
When RT Constraint is configured on a session that also supports VPN address families using route targets (that is: vpn-ipv4, vpn-ipv6, l2-vpn, mvpn-ipv4, mvpn-ipv6, mcast-vpn-ipv4 or evpn), the advertisement of the VPN routes is affected as follows:
- When the session comes up, the advertisement of the VPN routes is delayed for a short while to allow RTC routes to be received from the peer.
- After the initial delay, the received RTC routes are analyzed and acted upon. If S1 is the set of routes previously advertised to the peer and S2 is the set of routes that should be advertised based on the most recent received RTC routes then:
- Set of routes in S1 but not in S2 should be withdrawn immediately (subject to MRAI).
- Set of routes in S2 but not in S1 should be advertised immediately (subject to MRAI).
- If a default RTC route is received from a peer P1, the VPN routes that are advertised to P1 is the set that:
- are eligible for advertisement to P1 per BGP route advertisement rules AND
- have not been rejected by manually configured export policies AND
- have not been advertised to the peer

Note: This applies whether or not P1 advertised the best route for the default RTC prefix.
In this context, a default RTC route is any of the following:
- a route with NLRI length = zero
- a route with NLRI value = origin AS and NLRI length = 32
- a route with NLRI value = {origin AS+0x0002 | origin AS+0x0102 | origin AS+0x0202} and NLRI length = 48
- If an RTC route for prefix A (origin-AS = A1, RT = A2/n, n > 48) is received from an IBGP peer I1 in autonomous system A1, the VPN routes that are advertised to I1 is the set that:
- are eligible for advertisement to I1 per BGP route advertisement rules AND
- have not been rejected by manually configured export policies AND
- carry at least one route target extended community with value A2 in the n most significant bits AND
- have not been advertised to the peer
Note: This applies whether or not I1 advertised the best route for A.
- If the best RTC route for a prefix A (origin-AS = A1, RT = A2/n, n > 48) is received from an IBGP peer I1 in autonomous system B, the VPN routes that are advertised to I1 is the set that:
- are eligible for advertisement to I1 per BGP route advertisement rules AND
- have not been rejected by manually configured export policies AND
- carry at least one route target extended community with value A2 in the n most significant bits AND
- have not been advertised to the peer
Note: This applies only if I1 advertised the best route for A.
- If the best RTC route for a prefix A (origin-AS = A1, RT = A2/n, n > 48) is received from an EBGP peer E1, the VPN routes that are advertised to E1 is the set that:
- are eligible for advertisement to E1 per BGP route advertisement rules AND
- have not been rejected by manually configured export policies AN
- carry at least one route target extended community with value A2 in the n most significant bits AND
- have not been advertised to the peer
Note: This applies only if E1 advertised the best route for A.
3.1.7. BGP Fast Reroute in a VPRN
BGP fast reroute is a feature that brings together indirection techniques in the forwarding plane and pre-computation of BGP backup paths in the control plane to support fast reroute of BGP traffic around unreachable/failed next-hops. In a VPRN context BGP fast reroute is supported using unlabeled IPv4, unlabeled IPv6, VPN-IPv4, and VPN-IPv6 VPN routes. The supported VPRN scenarios are outlined in Table 31.
BGP fast reroute information specific to the base router BGP context is described in the BGP Fast Reroute section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR Unicast Routing Protocols Guide.
Table 31: BGP Fast Reroute Scenarios (VPRN Context)
Ingress Packet | Primary Route | Backup Route | Prefix Independent Convergence |
IPv4 (ingress PE) | IPv4 route with next-hop A resolved by an IPv4 route | IPv4 route with next-hop B resolved by an IPv4 route | Yes |
IPv4 (ingress PE) | VPN-IPv4 route with next-hop A resolved by a GRE, LDP, RSVP or BGP tunnel | VPN-IPv4 route with next-hop A resolved by a GRE, LDP, RSVP or BGP tunnel | Yes |
MPLS (egress PE) | IPv4 route with next-hop A resolved by an IPv4 route | IPv4 route with next-hop B resolved by an IPv4 route | Yes |
MPLS (egress PE) | IPv4 route with next-hop A resolved by an IPv4 rout | VPN-IPv4 route* with next-hop B resolved by a GRE, LDP, RSVP or BGP tunnel | Yes |
IPv6 (ingress PE) | IPv6 route with next-hop A resolved by an IPv6 route | IPv6 route with next-hop B resolved by an IPv6 route | Yes |
IPv6 (ingress PE) | VPN-IPv6 route with next-hop A resolved by a GRE, LDP, RSVP or BGP tunnel | VPN-IPv6 route with next-hop B resolved by a GRE, LDP, RSVP or BGP tunnel | Yes |
MPLS (egress) | IPv6 route with next-hop A resolved by an IPv6 route | IPv6 route with next-hop B resolved by an IPv6 route | Yes |
MPLS (egress) | IPv6 route with next-hop A resolved by an IPv6 route | Yes | VPRN label mode must be VRF. VPRN must export its VPN-IP routes with RD ≠ y. For the best performance the backup next-hop must advertise the same VPRN label value with all routes (e.g. per VRF label). |
3.1.7.1. BGP Fast Reroute in a VPRN Configuration
In a VPRN context, BGP fast reroute is optional and must be enabled. Fast reroute can be applied to all IPv4 prefixes, all IPv6 prefixes, all IPv4 and IPv6 prefixes, or to a specific set of IPv4 and IPv6 prefixes.
If all IP prefixes require backup path protection, use a combination of the BGP instance-level backup-path and VPRN-level enable-bgp-vpn-backup commands. The VPRN BGP backup-path command enables BGP fast reroute for all IPv4 prefixes and/or all IPv6 prefixes that have a best path through a VPRN BGP peer. The VPRN-level enable-bgp-vpn-backup command enables BGP fast reroute for all IPv4 prefixes and/or all IPv6 prefixes that have a best path through a remote PE peer.
If only some IP prefixes require backup path protection, use route policies to apply the install-backup-path action to the best paths of the IP prefixes requiring protection. See the “BGP Fast Reroute” section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR Unicast Routing Protocols Guide for more information.
3.1.8. BGP Best-External in a VPRN Context
If two or more PE routers connect to a multi-homed site and learn routes for a common set of IP prefixes from that site, then the failure of one of the PE routers or a PE-CE link can be handled by rerouting the traffic over the alternate paths. The traffic failover time in this situation can be reduced if all the PE routers have advance knowledge of the potential backup paths and do not have to wait for BGP route advertisements and/or withdrawals to reprogram their forwarding tables. This can be challenging with normal BGP procedures because a PE router is not allowed to advertise, to other PE routers, a BGP route that it has learned from a connected CE device if that route is not its active route for the destination in the route table. If the multi-homing scenario calls for all traffic destined for an IP prefix to be carried over a preferred primary path (passing through PE1-CE1 for example), then all other PE routers (PE2, PE3, and so on) will have that VPN route as their active route for the destination, and they will not be able to advertise their own routes for the same IP prefix.
The SR OS supports a VPRN feature, configured using the export-inactive-bgp command, that resolves the issue described above. When a VPRN is configured with this command, it is allowed to advertise (as a VPN-IP route towards other PEs) its best CE-BGP route for an IP prefix, even when that CE-BGP route is inactive in the route table due to the presence of a more-preferred VPN-IP route from another PE. In order for the CE-BGP route to be advertised, the CE-BGP route must be accepted by the VRF export policy. When a VPN-IP route is advertised due to the export-inactive-bgp command, the label carried in the route is a per-next-hop label corresponding to the next-hop IP address of the CE-BGP route, or a per-prefix label; this helps avoid packet looping issues due to unsynchronized IP FIBs.
When a PE router that advertised a backup path for an IP prefix receives a withdrawal for the VPN-IP route that it was using as the primary/active route, its backup path may be promoted to the primary path; that is, the CE-BGP route may become the active route for the destination. In this case, the PE router is required to re-advertise the VPN-IP route with a per-VRF label if that is the default allocation policy and there is no label-per-prefix policy override. It will take some time for the new VPN-IP route to reach all the ingress routers and for them to update their forwarding tables. In the meantime, traffic will continue to be received with the old per-next-hop label. The egress PE will drop this in-flight traffic unless label retention is configured using the bgp-labels-hold-timer command in the config>router>mpls-labels context. This command configures a delay (in seconds) between the withdrawal of a VPN-IP route with a per-next-hop label and the deletion of the corresponding label forwarding entry in the IOM. The value of bgp-labels-hold-timer should be large enough to account for the propagation delay of the route withdrawal to all the ingress routers.
3.2. VPRN Features
This section describes various VPRN features and any special capabilities or considerations as they relate to VPRN services.
3.2.1. IP Interfaces
VPRN customer IP interfaces can be configured with most of the same options found on the core IP interfaces. The advanced configuration options supported are:
- VRRP
- Cflowd
- Secondary IP addresses
- ICMP Options
Configuration options found on core IP interfaces not supported on VPRN IP interfaces are:
- NTP broadcast receipt
3.2.1.1. QoS Policy Propagation Using BGP (QPPB)
This section discusses QPPB as it applies to VPRN, IES, and router interfaces. Refer to the QoS Policy Propagation Using BGP (QPPB) section and the IP Router Configuration section in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Router Configuration Guide.
The QoS Policy Propagation Using BGP (QPPB) feature applies only to the 7450 ESS and 7750 SR.
QoS policy propagation using BGP (QPPB) is a feature that allows a route to be installed in the routing table with a forwarding-class and priority so that packets matching the route can receive the associated QoS. The forwarding-class and priority associated with a BGP route are set using BGP import route policies. In the industry, this feature is called QPPB, and even though the feature name refers to BGP specifically. On SR OS, QPPB is supported for BGP (IPv4, IPv6, VPN-IPv4, VPN-IPv6), RIP and static routes.
While SAP ingress and network QoS policies can achieve the same end result as QPPB, the effort involved in creating the QoS policies, keeping them up-to-date, and applying them across many nodes is much greater than with QPPB. This is due to assigning a packet, arriving on a particular IP interface, to a specific forwarding-class and priority/profile, based on the source IP address or destination IP address of the packet. In a typical application of QPPB, a BGP route is advertised with a BGP community attribute that conveys a particular QoS. Routers that receive the advertisement accept the route into their routing table and set the forwarding-class and priority of the route from the community attribute.
3.2.1.2. QPPB Applications
There are two typical applications of QPPB:
- coordination of QoS policies between different administrative domains, and
- traffic differentiation within a single domain, based on route characteristics.
3.2.1.3. Inter-AS Coordination of QoS Policies
The operator of an administrative domain A can use QPPB to signal to a peer administrative domain B that traffic sent to certain prefixes advertised by domain A should receive a particular QoS treatment in domain B. More specifically, an ASBR of domain A can advertise a prefix XYZ to domain B and include a BGP community attribute with the route. The community value implies a particular QoS treatment, as agreed by the two domains (in their peering agreement or service level agreement, for example). When the ASBR and other routers in domain B accept and install the route for XYZ into their routing table, they apply a QoS policy on selected interfaces that classifies traffic towards network XYZ into the QoS class implied by the BGP community value.
QPPB may also be used to request that traffic sourced from certain networks receive appropriate QoS handling in downstream nodes that may span different administrative domains. This can be achieved by advertising the source prefix with a BGP community, as discussed above. However, in this case other approaches are equally valid, such as marking the DSCP or other CoS fields based on source IP address so that downstream domains can take action based on a common understanding of the QoS treatment implied by different DSCP values.
In the above examples, coordination of QoS policies using QPPB could be between a business customer and its IP VPN service provider, or between one service provider and another.
3.2.1.4. Traffic Differentiation Based on Route Characteristics
There may be times when a network operator wants to provide differentiated service to certain traffic flows within its network, and these traffic flows can be identified with known routes. For example, the operator of an ISP network may want to give priority to traffic originating in a particular ASN (the ASN of a content provider offering over-the-top services to the ISP’s customers), following a certain AS_PATH, or destined for a particular next-hop (remaining on-net vs. off-net).
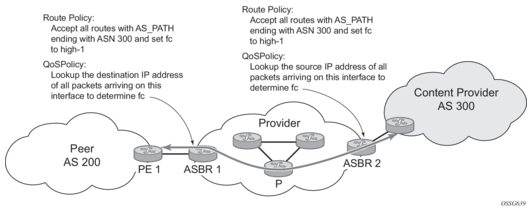
Figure 15 shows an example of an ISP that has an agreement with the content provider managing AS300 to provide traffic sourced and terminating within AS300 with differentiated service appropriate to the content being transported. In this example we presume that ASBR1 and ASBR2 mark the DSCP of packets terminating and sourced, respectively, in AS300 so that other nodes within the ISP’s network do not need to rely on QPPB to determine the correct forwarding-class to use for the traffic. The DSCP or other CoS markings could be left unchanged in the ISP’s network and QPPB used on every node.
Figure 15: Use of QPPB to Differentiate Traffic in an ISP Network
3.2.1.5. QPPB
There are two main aspects of the QPPB feature on the 7450 ESS and 7750 SR:
- the ability to associate a forwarding-class and priority with certain routes in the routing table, and
- the ability to classify an IP packet arriving on a particular IP interface to the forwarding-class and priority associated with the route that best matches the packet.
3.2.1.6. Associating an FC and Priority with a Route
This feature uses a command in the route-policy hierarchy to set the forwarding class and optionally the priority associated with routes accepted by a route-policy entry. The command has the following structure:
fc fc-name [priority {low | high}]
The use of this command is illustrated by the following example:
The fc command is supported with all existing from and to match conditions in a route policy entry and with any action other than reject, it is supported with next-entry, next-policy and accept actions. If a next-entry or next-policy action results in multiple matching entries then the last entry with a QPPB action determines the forwarding class and priority.
A route policy that includes the fc command in one or more entries can be used in any import or export policy but the fc command has no effect except in the following types of policies:
- VRF import policies:
- config>service>vprn>vrf-import
- BGP import policies:
- config>router>bgp>import
- config>router>bgp>group>import
- config>router>bgp>group>neighbor>import
- config>service>vprn>bgp>import
- config>service>vprn>bgp>group>import
- config>service>vprn>bgp>group>neighbor>import
- RIP import policies:
- config>router>rip>import
- config>router>rip>group>import
- config>router>rip>group>neighbor>import
- config>service>vprn>rip>import
- config>service>vprn>rip>group>import
- config>service>vprn>rip>group>neighbor>import
As evident from above, QPPB route policies support routes learned from RIP and BGP neighbors of a VPRN as well as for routes learned from RIP and BGP neighbors of the base/global routing instance.
QPPB is supported for BGP routes belonging to any of the address families listed below:
- IPv4 (AFI=1, SAFI=1)
- IPv6 (AFI=2, SAFI=1)
- VPN-IPv4 (AFI=1, SAFI=128)
- VPN-IPv6 (AFI=2, SAFI=128)
A VPN-IP route may match both a VRF import policy entry and a BGP import policy entry (if vpn-apply-import is configured in the base router BGP instance). In this case the VRF import policy is applied first and then the BGP import policy, so the QPPB QoS is based on the BGP import policy entry.
This feature also introduces the ability to associate a forwarding-class and optionally priority with IPv4 and IPv6 static routes. This is achieved by specifying the forwarding-class within the static-route-entry next-hop or indirect context.
Priority is optional when specifying the forwarding class of a static route, but once configured it can only be deleted and returned to unspecified by deleting the entire static route.
3.2.1.7. Displaying QoS Information Associated with Routes
The following commands are enhanced to show the forwarding-class and priority associated with the displayed routes:
- show router route-table
- show router fib
- show router bgp routes
- show router rip database
- show router static-route
This feature uses a qos keyword to the show>router>route-table command. When this option is specified the output includes an additional line per route entry that displays the forwarding class and priority of the route. If a route has no fc and priority information then the third line is blank. The following CLI shows an example:
show router route-table [family] [ip-prefix[/prefix-length]] [longer | exact] [protocol protocol-name] qos
An example output of this command is shown below:
3.2.1.8. Enabling QPPB on an IP interface
To enable QoS classification of ingress IP packets on an interface based on the QoS information associated with the routes that best match the packets the qos-route-lookup command is necessary in the configuration of the IP interface. The qos-route-lookup command has parameters to indicate whether the QoS result is based on lookup of the source or destination IP address in every packet. There are separate qos-route-lookup commands for the IPv4 and IPv6 packets on an interface, which allows QPPB to enabled for IPv4 only, IPv6 only, or both IPv4 and IPv6. Current QPPB based on a source IP address is not supported for IPv6 packets nor is it supported for ingress subscriber management traffic on a group interface.
The qos-route-lookup command is supported on the following types of IP interfaces:
- base router network interfaces (config>router>interface)
- VPRN SAP and spoke SDP interfaces (config>service>vprn>interface)
- VPRN group-interfaces (config>service>vprn>sub-if>grp-if)
- IES SAP and spoke SDP interfaces (config>service>ies>interface)
- IES group-interfaces (config>service>ies>sub-if>grp-if)
When the qos-route-lookup command with the destination parameter is applied to an IP interface and the destination address of an incoming IP packet matches a route with QoS information the packet is classified to the fc and priority associated with that route, overriding the fc and priority/profile determined from the SAP-Ingress or network qos policy associated with the IP interface. If the destination address of the incoming packet matches a route with no QoS information the fc and priority of the packet remain as determined by the SAP-Ingress or network qos policy.
Similarly, when the qos-route-lookup command with the source parameter is applied to an IP interface and the source address of an incoming IP packet matches a route with QoS information the packet is classified to the fc and priority associated with that route, overriding the fc and priority/profile determined from the SAP-Ingress or network qos policy associated with the IP interface. If the source address of the incoming packet matches a route with no QoS information the fc and priority of the packet remain as determined by the SAP-Ingress or network qos policy.
Currently, QPPB is not supported for ingress MPLS traffic on network interfaces or on CsC PE’-CE’ interfaces (config>service>vprn>nw-if).
3.2.1.9. QPPB When Next-Hops are Resolved by QPPB Routes
In some circumstances (IP VPN inter-AS model C, Carrier Supporting Carrier, indirect static routes, etc.) an IPv4 or IPv6 packet may arrive on a QPPB-enabled interface and match a route A1 whose next-hop N1 is resolved by a route A2 with next-hop N2 and perhaps N2 is resolved by a route A3 with next-hop N3, etc. The QPPB result is based only on the forwarding-class and priority of route A1. If A1 does not have a forwarding-class and priority association then the QoS classification is not based on QPPB, even if routes A2, A3, etc. have forwarding-class and priority associations.
3.2.1.10. QPPB and Multiple Paths to a Destination
When ECMP is enabled some routes may have multiple equal-cost next-hops in the forwarding table. When an IP packet matches such a route the next-hop selection is typically based on a hash algorithm that tries to load balance traffic across all the next-hops while keeping all packets of a given flow on the same path. The QPPB configuration model described in Associating an FC and Priority with a Route allows different QoS information to be associated with the different ECMP next-hops of a route. The forwarding-class and priority of a packet matching an ECMP route is based on the particular next-hop used to forward the packet.
When BGP FRR is enabled some BGP routes may have a backup next-hop in the forwarding table in addition to the one or more primary next-hops representing the equal-cost best paths allowed by the ECMP/multipath configuration. When an IP packet matches such a route a reachable primary next-hop is selected (based on the hash result) but if all the primary next-hops are unreachable then the backup next-hop is used. The QPPB configuration model described in Associating an FC and Priority with a Route allows the forwarding-class and priority associated with the backup path to be different from the QoS characteristics of the equal-cost best paths. The forwarding class and priority of a packet forwarded on the backup path is based on the fc and priority of the backup route.
3.2.1.11. QPPB and Policy-Based Routing
When an IPv4 or IPv6 packet with destination address X arrives on an interface with both QPPB and policy-based-routing enabled:
- There is no QPPB classification if the IP filter action redirects the packet to a directly connected interface, even if X is matched by a route with a forwarding-class and priority
- QPPB classification is based on the forwarding-class and priority of the route matching IP address Y if the IP filter action redirects the packet to the indirect next-hop IP address Y, even if X is matched by a route with a forwarding-class and priority.
3.2.1.12. QPPB and GRT Lookup
Source-address based QPPB is not supported on any SAP or spoke SDP interface of a VPRN configured with the grt-lookup command.
3.2.1.13. QPPB Interaction with SAP Ingress QoS Policy
When QPPB is enabled on a SAP IP interface the forwarding class of a packet may change from fc1, the original fc determined by the SAP ingress QoS policy to fc2, the new fc determined by QPPB. In the ingress datapath SAP ingress QoS policies are applied in the first P chip and route lookup/QPPB occurs in the second P chip. This has the implications listed below:
- Ingress remarking (based on profile state) is always based on the original fc (fc1) and sub-class (if defined).
- The profile state of a SAP ingress packet that matches a QPPB route depends on the configuration of fc2 only. If the de-1-out-profile flag is enabled in fc2 and fc2 is not mapped to a priority mode queue then the packet will be marked out of profile if its DE bit = 1. If the profile state of fc2 is explicitly configured (in or out) and fc2 is not mapped to a priority mode queue then the packet is assigned this profile state. In both cases there is no consideration of whether or not fc1 was mapped to a priority mode queue.
- The priority of a SAP ingress packet that matches a QPPB route depends on several factors. If the de-1-out-profile flag is enabled in fc2 and the DE bit is set in the packet then priority will be low regardless of the QPPB priority or fc2 mapping to profile mode queue, priority mode queue or policer. If fc2 is associated with a profile mode queue then the packet priority will be based on the explicitly configured profile state of fc2 (in profile = high, out profile = low, undefined = high), regardless of the QPPB priority or fc1 configuration. If fc2 is associated with a priority mode queue or policer then the packet priority will be based on QPPB (unless DE=1), but if no priority information is associated with the route then the packet priority will be based on the configuration of fc1 (if fc1 mapped to a priority mode queue then it is based on DSCP/IP prec/802.1p and if fc1 mapped to a profile mode queue then it is based on the profile state of fc1).
Table 32 summarizes these interactions.
Table 32: QPPB Interactions with SAP Ingress QoS
Original FC object mapping | New FC object mapping | Profile | Priority (drop preference) | DE=1 override | In/out of profile marking |
Profile mode queue | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default is high priority. | From new base FC | From original FC and sub-class |
Priority mode queue | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Policer | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Priority mode queue | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Policer | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then from original dot1p/exp/DSCP mapping or policy default. | From new base FC | From original FC and sub-class |
Profile mode queue | Priority mode queue | Ignored | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then follows original FC’s profile mode rules. | From new base FC | From original FC and sub-class |
Priority mode queue | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default is high priority. | From new base FC | From original FC and sub-class |
Profile mode queue | Policer | From new base FC unless overridden by DE=1 | If DE=1 override then low otherwise from QPPB. If no DEI or QPPB overrides then follows original FC’s profile mode rules. | From new base FC | From original FC and sub-class |
Policer | Profile mode queue | From new base FC unless overridden by DE=1 | From QPPB, unless packet is marked in or out of profile in which case follows profile. Default is high priority. | From new base FC | From original FC and sub-class |
3.2.1.14. Object Grouping and State Monitoring
This feature introduces a generic operational group object which associates different service endpoints (pseudowires and SAPs) located in the same or in different service instances. The operational group status is derived from the status of the individual components using certain rules specific to the application using the concept. A number of other service entities, the monitoring objects, can be configured to monitor the operational group status and to perform certain actions as a result of status transitions. For example, if the operational group goes down, the monitoring objects will be brought down.
3.2.1.15. VPRN IP Interface Applicability
This concept is used by an IPv4 VPRN interface to affect the operational state of the IP interface monitoring the operational group. Individual SAP and spoke SDPs are supported as monitoring objects.
The following rules apply:
- An object can only belong to one group at a time.
- An object that is part of a group cannot monitor the status of a group.
- An object that monitors the status of a group cannot be part of a group.
- An operational group may contain any combination of member types: SAP or Spoke-SDPs.
- An operational group may contain members from different VPLS service instances.
- Objects from different services may monitor the oper-group.
There are two steps involved in enabling the functionality:
- Identify a set of objects whose forwarding state should be considered as a whole group then group them under an operational group using the oper-group command.
- Associate the IP interface to the oper-group using the monitor-group command
The status of the operational group (oper-group) is dictated by the status of one or more members according to the following rule:
- The oper-group goes down if all the objects in the oper-group go down. The oper-group comes up if at least one of the components is up.
- An object in the group is considered down if it is not forwarding traffic in at least one direction. That could be because the operational state is down or the direction is blocked through some validation mechanism.
- If a group is configured but no members are specified yet then its status is considered up.
- As soon as the first object is configured the status of the operational group is dictated by the status of the provisioned member(s).
The simple configuration below shows the oper-group g1, the VPLS SAP that is mapped to it and the IP interfaces in VPRN service 2001 monitoring the oper-group g1. This is example uses an R-VPLS context. The VPLS instance includes the allow-ip-int-bind and the name v1. The VPRN interface links to the VPLS using the vpls v1 option. All commands are under the configuration service hierarchy.
To further explain the configuration. Oper-group g1 has a single SAP (1/1/1:2001) mapped to it and the IP interfaces in the VPRN service 2001 will derive its state from the state of oper-group g1.
3.2.2. Subscriber Interfaces
Subscriber interfaces are composed of a combination of two key technologies, subscriber interfaces and group interfaces. While the subscriber interface defines the subscriber subnets, the group interfaces are responsible for aggregating the SAPs.
Subscriber Interfaces apply only to the 7450 ESS and 7750 SR.
- Subscriber interface — an interface that allows the sharing of a subnet among one or many group interfaces in the routed CO model
- Group interface — aggregates multiple SAPs on the same port
- Redundant interfaces — a special spoke-terminated Layer 3 interface. It is used in a Layer 3 routed CO dual-homing configuration to shunt downstream (network to subscriber) to the active node for a given subscriber
3.2.3. SAPs
3.2.3.1. Encapsulations
The following SAP encapsulations are supported on the 7750 SR and 7950 XRS VPRN service:
- Ethernet null
- Ethernet dot1q
- SONET/SDH IPCP
- SONET/SDH ATM
- ATM - LLC SNAP or VC-MUX
- Cisco HDLC
- QinQ
- LAG
- Tunnel (IPSec or GRE)
- Frame Relay
3.2.3.2. ATM SAP Encapsulations for VPRN Services
The router supports ATM PVC service encapsulation for VPRN SAPs on the 7750 SR only. Both UNI and NNI cell formats are supported. The format is configurable on a SONET/SDH path basis. A path maps to an ATM VC. All VCs on a path must use the same cell format.
The following ATM encapsulation and transport modes are supported:
- RFC 2684, Multiprotocol Encapsulation over ATM Adaptation Layer 5:
- AAL5 LLC/SNAP IPv4 routed
- AAL5 VC mux IPv4 routed
- AAL5 LLC/SNAP IPv4 bridged
- AAL5 VC mux IPv4 bridged
3.2.3.3. Pseudowire SAPs
Pseudowire SAPs are supported on VPRN interfaces for the 7750 SR in the same way as on IES interfaces.
3.2.4. QoS Policies
When applied to a VPRN SAP, service ingress QoS policies only create the unicast queues defined in the policy if PIM is not configured on the associated IP interface; if PIM is configured, the multipoint queues are applied as well.
With VPRN services, service egress QoS policies function as with other services where the class-based queues are created as defined in the policy.
Both Layer 2 or Layer 3 criteria can be used in the QoS policies for traffic classification in an VPRN.
3.2.5. Filter Policies
Ingress and egress IPv4 and IPv6 filter policies can be applied to VPRN SAPs.
3.2.6. DSCP Marking
Specific DSCP, forwarding class, and Dot1P parameters can be specified to be used by every protocol packet generated by the VPRN. This enables prioritization or de-prioritization of every protocol (as required). The markings effect a change in behavior on ingress when queuing. For example, if OSPF is not enabled, then traffic can be de-prioritized to best effort (be) DSCP. This change de-prioritizes OSPF traffic to the CPU complex.
DSCP marking for internally generated control and management traffic by marking the DSCP value should be used for the given application. This can be configured per routing instance. For example, OSPF packets can carry a different DSCP marking for the base instance and then for a VPRN service. ISIS and ARP traffic is not an IP-generated traffic type and is not configurable.
When an application is configured to use a specified DSCP value then the MPLS EXP, Dot1P bits will be marked in accordance with the network or access egress policy as it applies to the logical interface the packet will be egressing.
The DSCP value can be set per application. This setting will be forwarded to the egress line card. The egress line card does not alter the coded DSCP value and marks the LSP-EXP and IEEE 802.1p (Dot1P) bits according to the appropriate network or access QoS policy.
Table 33: DSCP/FC Marking
Protocol | IPv4 | IPv6 | DSCP Marking | Dot1P Marking | Default FC |
ARP | — | — | — | Yes | NC |
BGP | Yes | Yes | Yes | Yes | NC |
BFD | Yes | — | Yes | Yes | NC |
RIP | Yes | Yes | Yes | Yes | NC |
PIM (SSM) | Yes | Yes | Yes | Yes | NC |
OSPF | Yes | Yes | Yes | Yes | NC |
SMTP | Yes | — | — | — | AF |
IGMP/MLD | Yes | Yes | Yes | Yes | AF |
Telnet | Yes | Yes | Yes | Yes | AF |
TFTP | Yes | — | Yes | Yes | AF |
FTP | Yes | — | — | — | AF |
SSH (SCP) | Yes | Yes | Yes | Yes | AF |
SNMP (get, set, etc.) | Yes | Yes | Yes | Yes | AF |
SNMP trap/log | Yes | Yes | Yes | Yes | AF |
syslog | Yes | Yes | Yes | Yes | AF |
OAM ping | Yes | Yes | Yes | Yes | AF |
ICMP ping | Yes | Yes | Yes | Yes | AF |
Traceroute | Yes | Yes | Yes | Yes | AF |
TACPLUS | Yes | Yes | Yes | Yes | AF |
DNS | Yes | Yes | Yes | Yes | AF |
SNTP/NTP | Yes | — | — | — | AF |
RADIUS | Yes | — | — | — | AF |
Cflowd | Yes | — | — | — | AF |
DHCP 7450 ESS and 7750 SR only | Yes | Yes | Yes | Yes | AF |
Bootp | Yes | — | — | — | AF |
IPv6 Neighbor Discovery | Yes | — | — | — | NC |
3.2.6.1. Default DSCP Mapping Table
*The default forwarding class mapping is used for all DSCP names/values for which there is no explicit forwarding class mapping.
3.2.7. Configuration of TTL Propagation for VPRN Routes
This feature allows the separate configuration of TTL propagation for in transit and CPM generated IP packets, at the ingress LER within a VPRN service context. The following commands are supported:
- config router ttl-propagate vprn-local [none | vc-only | all]
- config router ttl-propagate vprn-transit [none | vc-only | all]
You can enable TTL propagation behavior separately as follows:
- for locally generated packets by CPM (vprn-local)
- for user and control packets in transit at the node (vprn-transit)
The following parameters can be specified:
- The all parameter enables TTL propagation from the IP header into all labels in the stack, for VPN-IPv4 and VPN-IPv6 packets forwarded in the context of all VPRN services in the system.
- The vc-only parameter reverts to the default behavior by which the IP TTL is propagated into the VC label but not to the transport labels in the stack. You can explicitly set the default behavior by configuring the vc-only value.
- The none parameter disables the propagation of the IP TTL to all labels in the stack, including the VC label. This is needed for a transparent operation of UDP traceroute in VPRN inter-AS Option B such that the ingress and egress ASBR nodes are not traced.
This command does not use a no version.
The user can override the global configuration within each VPRN instance using the following commands:
- config service vprn ttl-propagate local [inherit | none | vc-only | all]
- config service vprn ttl-propagate transit [inherit | none | vc-only | all]
The default behavior for a VPRN instance is to inherit the global configuration for the same command. You can explicitly set the default behavior by configuring the inherit value.
This command does not have a no version.
The commands do not apply when the VPRN packet is forwarded over GRE transport tunnel.
If a packet is received in a VPRN context and a lookup is done in the Global Routing Table (GRT), (when leaking to GRT is enabled for example), the behavior of the TTL propagation is governed by the LSP shortcut configuration as follows:
- when the matching route is an RSVP LSP shortcut:
- configure router mpls shortcut-transit-ttl-propagate
- when the matching route is an LDP LSP shortcut:
- configure router ldp shortcut-transit-ttl-propagate
When the matching route is a RFC 3107 label route or a 6PE route, It is governed by the BGP label route configuration
When a packet is received on one VPRN instance and is redirected using Policy Based Routing (PBR) to be forwarded in another VPRN instance, the TTL propagation is governed by the configuration of the outgoing VPRN instance.
Packets that are forwarded in different contexts can use different TTL propagation over the same BGP tunnel, depending on the TTL configuration of each context. An example of this might be VPRN using a BGP tunnel and an IPv4 packet forwarded over a BGP label route of the same prefix as the tunnel.
3.2.8. CE to PE Routing Protocols
The 7750 SR and 7950 XRS VPRN supports the following PE to CE routing protocols:
- BGP
- Static
- RIP
- OSPF
3.2.8.1. PE to PE Tunneling Mechanisms
The 7750 SR and 7950 XRS support multiple mechanisms to provide transport tunnels for the forwarding of traffic between PE routers within the 2547bis network.
The 7750 SR and 7950 XRS VPRN implementation supports the use of:
- RSVP-TE protocol to create tunnel LSPs between PE routers
- LDP protocol to create tunnel LSP's between PE routers
- GRE tunnels between PE routers
These transport tunnel mechanisms provide the flexibility of using dynamically created LSPs where the service tunnels are automatically bound (the autobind feature) and the ability to provide certain VPN services with their own transport tunnels by explicitly binding SDPs if desired. When the autobind is used, all services traverse the same LSPs and do not allow alternate tunneling mechanisms (like GRE) or the ability to craft sets of LSPs with bandwidth reservations for specific customers as is available with explicit SDPs for the service.
3.2.8.2. Per VRF Route Limiting
The 7750 SR and 7950 XRS allow setting the maximum number of routes that can be accepted in the VRF for a VPRN service. There are options to specify a percentage threshold at which to generate an event that the VRF table is near full and an option to disable additional route learning when full or only generate an event.
3.2.9. Spoke SDPs
Distributed services use service distribution points (SDPs) to direct traffic to another router via service tunnels. SDPs are created on each participating router and then bound to a specific service. SDP can be created as either GRE or MPLS. Refer to the 7450 ESS, 7750 SR, 7950 XRS, and VSR Services Overview Guide for information about configuring SDPs.
This feature provides the ability to cross-connect traffic entering on a spoke SDP, used for Layer 2 services (VLLs or VPLS), on to an IES or VPRN service. From a logical point of view, the spoke SDP entering on a network port is cross-connected to the Layer 3 service as if it entered by a service SAP. The main exception to this is traffic entering the Layer 3 service by a spoke SDP is handled with network QoS policies not access QoS policies.
Figure 16 depicts traffic terminating on a specific IES or VPRN service that is identified by the sdp-id and VC label present in the service packet.
Figure 16: SDP-ID and VC Label Service Identifiers
Refer to “VCCV BFD support for VLL, Spoke SDP Termination on IES and VPRN, and VPLS Services” in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Layer 2 Services and EVPN Guide: VLL, VPLS, PBB, and EVPN for information about using VCCV BFD in spoke-SDP termination.
| Note: Spoke-SDP termination of Ipipe VLLs on VPRN is not supported in System Profile B. To determine if Ipipes are currently bound to an VPRN interface, use the show router ldp bindings services command before configuring profile B. |
3.2.9.1. T-LDP Status Signaling for Spoke-SDPs Terminating on IES/VPRN
T-LDP status signaling and PW active/standby signaling capabilities are supported on ipipe and epipe spoke SDPs.
Spoke SDP termination on an IES or VPRN provides the ability to cross-connect traffic entering on a spoke SDP, used for Layer 2 services (VLLs or VPLS), on to an IES or VPRN service. From a logical point of view the spoke SDP entering on a network port is cross-connected to the Layer 3 service as if it had entered using a service SAP. The main exception to this is traffic entering the Layer 3 service using a spoke SDP is handled with network QoS policies instead of access QoS policies.
When a SAP down or SDP binding down status message is received by the PE in which the Ipipe or Ethernet Spoke-SDP is terminated on an IES or VPRN interface, the interface is brought down and all associated routes are withdrawn in a similar way when the Spoke-SDP goes down locally. The same actions are taken when the standby T-LDP status message is received by the IES/VPRN PE.
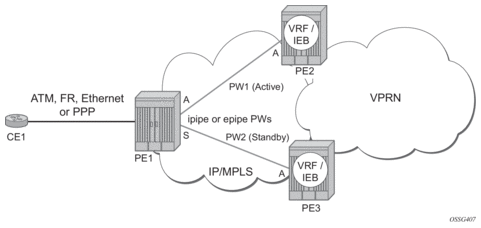
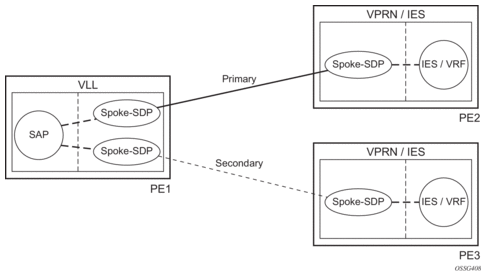
This feature can be used to provide redundant connectivity to a VPRN or IES from a PE providing a VLL service, as shown in Figure 17.
Figure 17: Active/Standby VRF Using Resilient Layer 2 Circuits
3.2.9.2. Spoke SDP Redundancy into IES/VPRN
This feature can be used to provide redundant connectivity to a VPRN or IES from a PE providing a VLL service, as shown in Figure 17, using either Epipe or Ipipe spoke-SDPs. This feature is supported on the 7450 ESS and 7750 SR only.
In Figure 17, PE1 terminates two spoke-SDPs that are bound to one SAP connected to CE1. PE1 chooses to forward traffic on one of the spoke SDPs (the active spoke-SDP), while blocking traffic on the other spoke-SDP (the standby spoke-SDP) in the transmit direction. PE2 and PE3 take any spoke-SDPs for which PW forwarding standby has been signaled by PE1 to an operationally down state.
The 7450 ESS, 7750 SR, and 7950 XRS routers are expected to fulfill both functions (VLL and VPRN/IES PE), while the 7705 SAR must be able to fulfill the VLL PE function. Figure 18 illustrates the model for spoke-SDP redundancy into a VPRN or IES.
Figure 18: Spoke-SDP Redundancy Model
3.2.10. IP-VPNs
3.2.10.1. Using OSPF in IP-VPNs
Using OSPF as a CE to PE routing protocol allows OSPF that is currently running as the IGP routing protocol to migrate to an IP-VPN backbone without changing the IGP routing protocol, introducing BGP as the CE-PE or relying on static routes for the distribution of routes into the service providers IP-VPN. The following features are supported:
- Advertisement/redistribution of BGP-VPN routes as summary (type 3) LSAs flooded to CE neighbors of the VPRN OSPF instance. This occurs if the OSPF route type (in the OSPF route type BGP extended community attribute carried with the VPN route) is not external (or NSSA) and the locally configured domain-id matches the domain-id carried in the OSPF domain ID BGP extended community attribute carried with the VPN route.
- OSPF sham links. A sham link is a logical PE-to-PE unnumbered point-to-point interface that essentially rides over the PE-to-PE transport tunnel. A sham link can be associated with any area and can therefore appear as an intra-area link to CE routers attached to different PEs in the VPN.
3.2.11. IPCP Subnet Negotiation
This feature enables negotiation between Broadband Network Gateway (BNG) and customer premises equipment (CPE) so that CPE is allocated both ip-address and associated subnet.
Some CPEs use the network up-link in PPPoE mode and perform dhcp-server function for all ports on the LAN side. Instead of wasting 1 subnet for p2p uplink, CPEs use allocated subnet for LAN portion as shown in Figure 19.
Figure 19: CPEs Network Up-link Mode
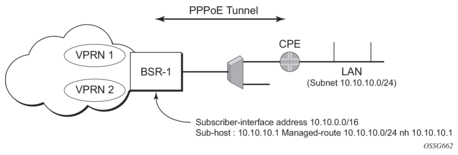
From a BNG perspective, the given PPPoE host is allocated a subnet (instead of /32) by RADIUS, external dhcp-server, or local-user-db. And locally, the host is associated with managed-route. This managed-route will be subset of the subscriber-interface subnet (on a 7450 ESS or 7750 SR), and also, subscriber-host ip-address will be from managed-route range. The negotiation between BNG and CPE allows CPE to be allocated both ip-address and associated subnet.
3.2.12. Cflowd for IP-VPNs
The cflowd feature allows service providers to collect IP flow data within the context of a VPRN. This data can used to monitor types and general proportion of traffic traversing an VPRN context. This data can also be shared with the VPN customer to see the types of traffic traversing the VPN and use it for traffic engineering.
This feature should not be used for billing purposes. Existing queue counters are designed for this purpose and provide very accurate per bit accounting records.
3.2.13. Inter-AS VPRNs
Inter-AS IP-VPN services have been driven by the popularity of IP services and service provider expansion beyond the borders of a single Autonomous System (AS) or the requirement for IP VPN services to cross the AS boundaries of multiple providers. Three options for supporting inter-AS IP-VPNs are described in RFC 4364, BGP/MPLS IP Virtual Private Networks (VPNs).
This feature applies to the 7450 ESS and 7750 SR only.
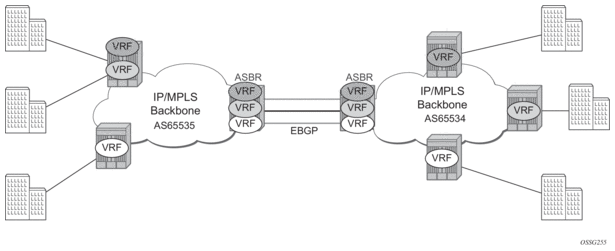
The first option, referred to as Option-A (Figure 20), is considered inherent in any implementation. This method uses a back-to-back connection between separate VPRN instances in each AS. As a result, each VPRN instance views the inter-AS connection as an external interface to a remote VPRN customer site. The back-to-back VRF connections between the ASBR nodes require individual sub-interfaces, one per VRF.
Figure 20: Inter-AS Option-A: VRF-to-VRF Model
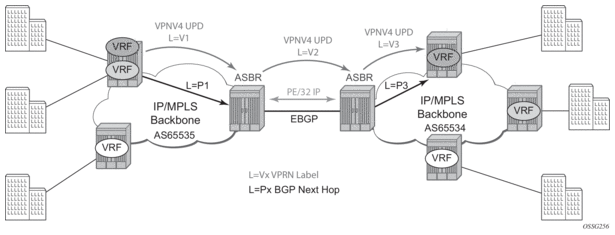
The second option, referred to as Option-B (Figure 21), relies heavily on the AS Boundary Routers (ASBRs) as the interface between the autonomous systems. This approach enhances the scalability of the eBGP VRF-to-VRF solution by eliminating the need for per-VPRN configuration on the ASBR(s). However it requires that the ASBR(s) provide a control plan and forwarding plane connection between the autonomous systems. The ASBR(s) are connected to the PE nodes in its local autonomous system using iBGP either directly or through route reflectors. This means the ASBR(s) receive all the VPRN information and will forward these VPRN updates, VPN-IPV4, to all its EBGP peers, ASBR(s), using itself as the next-hop. It also changes the label associated with the route. This means the ASBR(s) must maintain an associate mapping of labels received and labels issued for those routes. The peer ASBR(s) will in turn forward those updates to all local IBGP peers.
Figure 21: Inter-AS Option-B
This form of inter-AS VPRNs performs all necessary mapping functions and the PE routers do not need to perform any additional functions than in a non-Inter-AS VPRN.
On the 7750 SR, this form of inter-AS VPRNs does not require instances of the VPRN to be created on the ASBR, as in option-A, as a result there is less management overhead. This is also the most common form of Inter-AS VPRNs used between different service providers as all routes advertised between autonomous systems can be controlled by route policies on the ASBRs by the config>router>bgp>transport-tunnel CLI command. The third option, referred to as Option-C (Figure 22), allows for a higher scale of VPRNs across AS boundaries but also expands the trust model between ASNs. As a result this model is typically used within a single company that may have multiple ASNs for various reasons. This model differs from Option-B, in that in Option-B all direct knowledge of the remote AS is contained and limited to the ASBR. As a result, in option-B the ASBR performs all necessary mapping functions and the PE routers do not need to perform any additional functions than in a non-Inter-AS VPRN.
Figure 22: Option C Example
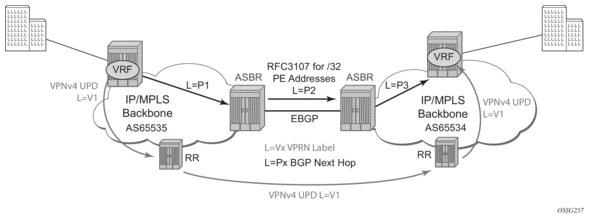
With Option-C, knowledge from the remote AS is distributed throughout the local AS. This distribution allows for higher scalability but also requires all PEs and ASBRs involved in the Inter-AS VPRNs to participate in the exchange of inter-AS routing information.
In Option-C, the ASBRs distribute reachability information for remote PE’s system IP addresses only. This is done between the ASBRs by exchanging MP-eBGP labeled routes, using RFC 3107, Carrying Label Information in BGP-4. Either RSVP-TE or LDP LSP can be selected to resolve next-hop for multi-hop eBGP peering by the config>router>bgp>transport-tunnel CLI command.
Distribution of VPRN routing information is handled by either direct MP-BGP peering between PEs in the different ASNs or more likely by one or more route reflectors in ASN.
3.2.14. VPRN Label Security at Inter-AS Boundary
This feature allows the user to enforce security at an inter-AS boundary and to configure a router, acting in a PE role and/or in an ASBR role, to accept packets of VPRN prefixes only from direct eBGP neighbors to which it advertised a VPRN label.
3.2.14.1. Feature Configuration
To use this feature, network IP interfaces that can have the feature enabled must first be identified. Participating interfaces are identified as having the untrusted state. The router supports a maximum of 15 network interfaces that can participate in this feature.
The following command is used to enable or disable this feature.
config>router>interface>untrusted [default-forwarding {forward | drop}]
Normally, the user applies the untrusted command to an inter-AS interface and PIP keeps track of the untrusted status of each interface. In the data path, an inter-AS interface that is flagged by PIP will cause the default forwarding to be set to the value of the default-forwarding keyword (forward or drop).
For backward compatibility, default-forwarding on the interface is set to the forward value. This means that labeled packets will be checked in the normal way against the table of programmed ILMs to decide if it should be dropped or forwarded in a GRT, a VRF, or a Layer 2 service context.
If the user sets the default-forwarding argument to the drop value, all labeled packets received on that interface are dropped. For details, see Data Path Forwarding Behavior.
This feature sets the default behavior for an untrusted interface in the data path and for all ILMs. To allow the data path to provide an exception to the normal way of forwarding handling away from the default for VPRN ILMs, BGP must flag those ILMs to the data path.
The user enables exceptional ILM forwarding behavior, on a per-VPN-family basis, by using the following command:
configure>router>bgp>neighbor-trust [vpn-ipv4] [vpn-ipv6]
At a high level, BGP tracks each direct eBGP neighbor over an untrusted interface and to which it sent a VPRN prefix label. For each of those VPRN prefixes, BGP programs a bit map in the ILM that indicates, on a per-untrusted interface basis, whether the matching packets must be forwarded or dropped. For details, see CPM Behavior.
3.2.14.2. CPM Behavior
This feature affects PIP behavior for management of network IP interfaces and in BGP for the resolution of BGP VPN-IPv4 and VPN-IPv6 prefixes.
The following are characteristics of CPM behavior related to PIP and the VPRN label security at inter-AS boundary feature:
- PIP manages the status of an untrusted interface based on the user configuration on the interface, as described in Feature Configuration. It programs the interface record in the data path using a 4-bit untrusted interface identification number. A trusted interface has no untrusted record.
- BGP determines the status of trusted or untrusted of an eBGP neighbor by checking the untrusted record provided by PIP for the index of the interface used by the eBGP session to the neighbor.
- BGP only tracks the status of trusted or untrusted for directly connected eBGP neighbors. The neighbor address and the local address must be on the same local subnet.
- BGP includes the neighbor status of trusted or untrusted in the tribe criteria. For example, if a group consists of two untrusted eBGP neighbors and one trusted eBGP neighbor and all three neighbors have the same local-AS, neighbor-AS, and export policy, then the result is two different tribes.As a result, if the interface status changes from trusted to untrusted or vice-versa, the eBGP neighbors on that interface will bounce.
- When the feature is enabled for a specified VPN family and BGP advertises a label for one or more resolved VPN prefixes to a group of trusted and untrusted eBGP neighbors, it creates a 16-bit map in the ILM record in which it sets the bit position corresponding to the identification number of each untrusted interface used by a eBGP session to a neighbor to which it sent the label.A bit in the ILM record bit-map is referred to as the untrusted interface forwarding bit. The bit position corresponding to the identification number of any other untrusted interface is left clear.For details on the data path of the ILM bit-map record, see Data Path Forwarding Behavior.
- Since the same label value is advertised for prefixes in the same VRF (label per-VRF mode) and for prefixes with the same next hop (label per-next-hop mode), BGP programs the forwarding bit position in the ILM bit map for both VPN IPv4 and VPN IPv6 prefixes sharing the same label, as long as the feature is enabled for at least one of the two VPN families.
- BGP tracks, on a per-untrusted interface basis, the number of RIB-Out entries to eBGP neighbors that reference a specific VPN label. When that reference transitions from zero to a positive value or from a positive value to zero, the label for the ILM of the VPN prefix is re-downloaded to the IOM with the forwarding bit position in the ILM bit map record updated accordingly (set or unset, respectively).
This feature supports label per-VRF and label per-next-hop modes for the PE role. The feature supports label per-next-hop mode for the ASBR role.
The feature is not supported with label per-prefix mode in a PE role and is not supported in a Carrier Supporting Carrier (CSC) PE role.
3.2.14.3. Data Path Forwarding Behavior
ILM forwarding on a trusted interface behaves as in prior releases and is not changed. The ILM forwarding bit map is ignored and packets are forwarded normally.
ILM forwarding on an untrusted interface follows these rules.
- Only the top-most label in the label stack in a received packet is checked against the next set of rules. The top label can correspond to any one of the following applications:
- a transport label with a pop or swap operation: static, RSVP-TE, SR-TE, LDP, SR-ISIS, SR-OSPF, or BGP-LU
- a BGP VPRN inter-AS option B label with a swap operation when the router acts in the ASBR role for VPN routes
- a service delimiting label for a local VRF when the router acts as a PE in a VPRN service
- The data path checks the bit position in the bit map in the ILM record, when present, that corresponds to the untrusted interface identification number in the interface record and then makes a forwarding decision to drop or forward.A decision to forward means that a labeled packet proceeds to the regular ILM processing and its label stack is checked against the table of programmed ILMs to decide if the packet should be:
- dropped
- forwarded to CPM
- forwarded as an MPLS packet
- forwarded as an IP packet in a GRT or a VRF context
- forwarded as a packet in a Layer 2 service context
- The following are the processing rules of the ILM:
- interface default-forwarding=forward and ILM bit-map not present ⇒ forward packet
- interface default-forwarding=forward and interface forwarding bit position in the ILM bit-map 1 ⇒ forward packet
- interface default-forwarding=forward and interface forwarding bit position in the ILM bit-map zero ⇒ drop packet
- interface default-forwarding=drop and ILM bit-map not present ⇒ drop packet
- interface default-forwarding=drop and interface forwarding bit position in the ILM bit-map zero ⇒ drop packet
- interface default-forwarding=drop and interface forwarding bit position in the ILM bit-map 1 ⇒ forward packet
- When the eBGP neighbor is not directly connected, BGP will not track that neighbor (see CPM Behavior). In this case, the VPRN packet is received with a transport label or without a transport label if implicit-null is enabled in LDP or RSVP-TE for the transport label. Either way, the forwarding decision for the packet is solely dictated by the configuration of the default-forwarding value on the incoming interface.
- If the direct eBGP neighbor sends a VPRN packet using the MPLS-over-GRE encapsulation, the data path does not check the interface forwarding bit position in the ILM bit map. In this case, the forwarding decision of the packet is solely dictated by the configuration of the default-forwarding value on the incoming interface.SR OS eBGP neighbors never use the MPLS-over-GRE encapsulation over an inter-AS link, but third party implementations might do this.
3.2.15. Carrier Supporting Carrier (CSC)
Carrier Supporting Carrier (CSC) is a solution for the 7750 SR and 7950 XRS that allows one service provider (the Customer Carrier) to use the IP VPN service of another service provider (the Super Carrier) for some or all of its backbone transport. RFC 4364 defines a Carrier Supporting Carrier solution for BGP/MPLS IP VPNs that uses MPLS on the interconnections between the two service providers in order to provide a scalable and secure solution.
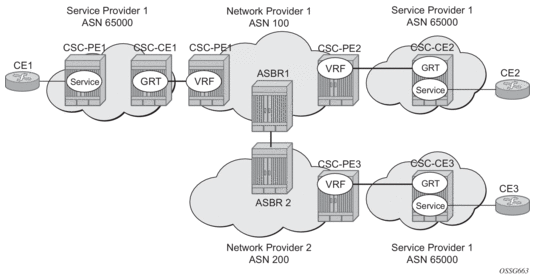
CSC support in SR OS allows a 7750 SR or 7950 XRS to be deployed as any of the following devices shown in Figure 23:
- PE1 (service provider PE)
- CSC-CE1, CSC-CE2 and CSC-CE3 (CE device from the point of view of the backbone service provider)
- CSC-PE1, CSC-PE2 and CSC-PE3 (PE device of the backbone service provider)
- ASBR1 and ASBR2 (ASBR of the backbone service provider)
Figure 23: Carrier Supporting Carrier Reference Diagram
3.2.15.1. Terminology
CE — customer premises equipment dedicated to one particular business/enterprise
PE — service provider router that connects to a CE to provide a business VPN service to the associated business/enterprise
CSC-CE — an ASBR/peering router that is connected to the CSC-PE of another service provider for purposes of using the associated CsC IP VPN service for backbone transport
CSC-PE — a PE router belonging to the backbone service provider that supports one or more CSC IP VPN services
3.2.15.2. CSC Connectivity Models
A PE router deployed by a customer service provider to provide Internet access, IP VPNs, and/or L2 VPNs may connect directly to a CSC-PE device, or it may back haul traffic within its local “site” to the CSC-CE that provides this direct connection. Here, “site” means a set of routers owned and managed by the customer service provider that can exchange traffic through means other than the CSC service. The function of the CSC service is to provide IP/MPLS reachability between isolated sites.
The CSC-CE is a “CE” from the perspective of the backbone service provider. There may be multiple CSC-CEs at a given customer service provider site and each one may connect to multiple CSC-PE devices for resiliency/multi-homing purposes.
The CSC-PE is owned and managed by the backbone service provider and provides CSC IP VPN service to connected CSC-CE devices. In many cases, the CSC-PE also supports other services, including regular business IP VPN services. A single CSC-PE may support multiple CSC IP VPN services. Each customer service provider is allocated its own VRF within the CSC-PE; VRFs maintain routing and forwarding separation and permit the use of overlapping IP addresses by different customer service providers.
A backbone service provider may not have the geographic span to connect, with reasonable cost, to every site of a customer service provider. In this case, multiple backbone service providers may coordinate to provide an inter-AS CSC service. Different inter-AS connectivity options are possible, depending on the trust relationships between the different backbone service providers.
The CSC Connectivity Models apply to the 7750 SR and 7950 XRS only.
3.2.15.3. CSC-PE Configuration and Operation
This section applies to CSC-PE1, CSC-PE2 and CSC-PE3 in Carrier Supporting Carrier Reference Diagram.
This section applies only to the 7750 SR.
3.2.15.4. CSC Interface
From the point of view of the CSC-PE, the IP/MPLS interface between the CSC-PE and a CSC-CE has these characteristics:
- The CSC interface is associated with one (and only one) VPRN service. Routes with the CSC interface as next-hop are installed only in the routing table of the associated VPRN.
- The CSC interface supports EBGP or IBGP for exchanging labeled IPv4 routes (RFC 3107). The BGP session may be established between the interface addresses of the two routers or else between a loopback address of the CSC-PE VRF and a loopback address of the CSC-CE. In the latter case, the BGP next-hop is resolved by either a static or OSPFv2 route.
- An MPLS packet received on a CSC interface is dropped if the top-most label was not advertised over a BGP (RFC 3107) session associated with one of the VPRN’s CSC interfaces.
- The CSC interface supports ingress QoS classification based on 802.1p or MPLS EXP. It is possible to configure a default FC and default profile for the CSC interface.
- The CSC interface supports QoS (re)marking for egress traffic. Policies to remark 802.1p or MPLS EXP based on forwarding-class and profile are configurable per CSC interface.
- By associating a port-based egress queue group instance with a CSC interface, the egress traffic can be scheduled/shaped with per-interface, per-forwarding-class granularity.
- By associating a forwarding-plane based ingress queue group instance with a CSC interface, the ingress traffic can be policed to per-interface, per-forwarding-class granularity.
- Ingress and egress statistics and accounting are available per CSC interface. The exact set of collected statistics depends on whether a queue-group is associated with the CSC interface, the traffic direction (ingress vs. egress), and the stats mode of the queue-group policers.
An Ethernet port or LAG with a CSC interface can be configured in hybrid mode or network mode. The port or LAG supports null, dot1q or qinq encapsulation. To create a CSC interface on a port or LAG in null mode, the following commands are used:
config>service>vprn>nw-if>port port-id config>service>vprn>nw-if>lag lag-id
To create a CSC interface on a port or LAG in dot1q mode, the following commands are used:
config>service>vprn>nw-if>port port-id:qtag1 config>service>vprn>nw-if>lag port-id:qtag1
To create a CSC interface on a port or LAG in qinq mode, the following commands are used:
config>service>vprn>nw-if>port port-id:qtag1.qtag2 config>service>vprn>nw-if>port port-id:qtag1.* config>service>vprn>nw-if>lag port-id:qtag1.qtag2 config>service>vprn>nw-if>lag port-id:qtag1.*
A CSC interface supports the same capabilities (and supports the same commands) as a base router network interface except it does not support:
- IPv6
- LDP
- RSVP
- Proxy ARP (local/remote)
- Network domain configuration
- DHCP
- Ethernet CFM
- Unnumbered interfaces
3.2.15.5. QoS
Egress
Egress traffic on a CSC interface can be shaped and scheduled by associating a port-based egress queue-group instance with the CSC interface. The steps for doing this are summarized below:
- Create an egress queue-group-template.
- Define one or more queues in the egress queue-group. For each one specify scheduling parameters such as CIR, PIR, CBS and MBS and, if using H-QoS, the parent scheduler.
- Apply an instance of the egress queue-group template to the network egress context of the Ethernet port with the CSC interface. When doing so, and if applicable, associate an accounting policy and/or a scheduler policy with this instance.
- Create a network QoS policy.
- In the egress part of the network QoS policy define EXP remarking rules, if necessary.
- In the egress part of the network QoS policy map a forwarding-class to a queue-id using the port-redirect-group command. For example:config>qos>network>egress>fc$ port-redirect-group queue 5
- Apply the network QoS policy created in step 4 to the CSC interface and specify the name of the egress queue-group created in step 1 and the specific instance defined in Step 3.
Ingress
Ingress traffic on a CSC interface can be policed by associating a forwarding-plane based ingress queue-group instance with the CSC interface. The steps for doing this are summarized below:
- Create an ingress queue-group-template.
- Define one or more policers in the ingress queue-group. For each one specify parameters such as CIR, PIR, CBS and MBS and, if using H-Pol, the parent arbiter.
- Apply an instance of the ingress queue-group template to the network ingress context of the forwarding plane with the CSC interface. When doing so, and if applicable, associate an accounting policy and/or a policer-control-policy with this instance.
- Create a network QoS policy.
- In the ingress part of the network QoS policy define EXP classification rules, if necessary.
- In the ingress part of the network QoS policy map a forwarding-class to a policer-id using the fp-redirect-group policer command. For example:config>qos>network>ingress>fc$ fp-redirect-group policer 5
- Apply the network QoS policy created in step 4 to the CSC interface and specify the name of the ingress queue-group created in step 1 and the specific instance defined in step 3.
3.2.15.6. MPLS
BGP-3107 is used as the label distribution protocol on the CSC interface. When BGP in a CSC VPRN needs to distribute a label corresponding to a received VPN-IPv4 route, it takes the label from the global label space. The allocated label will not be re-used for any other FEC regardless of the routing instance (base router or VPRN). If a label L is advertised to the BGP peers of CSC VPRN A then a received packet with label L as the top most label is only valid if received on an interface of VPRN A, otherwise the packet is discarded.
To use BGP-3107 as the label distribution protocol on the CSC interface, add the family label-ipv4 command to the family configuration at the instance, group, or neighbor level. This causes the capability to send and receive labeled-IPv4 routes {AFI=1, SAFI=4} to be negotiated with the CSC-CE peers.
3.2.15.7. CSC VPRN Service Configuration
To configure a VPRN to support CSC service, the carrier-carrier-vpn command must be enabled in its configuration. The command will fail if the VPRN has any existing SAP or spoke-SDP interfaces. A CSC interface can be added to a VPRN (using the network-interface command) only if the carrier-carrier-vpn command is present.
A VPRN service with the carrier-carrier-vpn command may be provisioned to use auto-bind-tunnel, configured spoke SDPs or some combination. All SDP types are supported except for:
• GRE SDPs
• LDP over RSVP-TE tunnel SDPs
Other aspects of VPRN configuration are the same in a CSC model as in a non-CSC model.
3.2.16. Node Management Using VPRN
Node management can be enabled using the local interface of any VPRN. A management VPRN is separated from other traffic using an MPLS transport tunnel. This provides IP domain separation and security for the management domain. The management domain supports IPv4 and IPv6 address families and the AAA server is connected to the same VPRN for authentication, authorization, and accounting. SR OS allows management using a VPRN as long the management packet is destined to a local interface of the VPRN, in addition it allows configuration of the AAA servers within a VPRN; see Figure 24.
| Note: The NSP cannot discover the node using any VPRN interfaces. If node discovery is required, then t GRT-LEAKING to the system IP address must be enabled. NSP can only discover the node using the system IP address in GRT. |
Figure 24: VF Network Example
3.2.16.1. VPRN Management
VPRN management can be enabled by enabling the appropriate management protocol within the VPRN from the vprn>management context. The following protocols are supported:
- FTP
- SSH
- Telnet
- Telnetv6
By default, all protocols are disabled. When one of these protocols is enabled, that VRF becomes a management VRF.
| Note: An SSH server can only be enabled or disabled in VPRN. All other SSH configurations such as the SSH version, key re-exchange, SSH client/server HMAC/Cipher list, and so on are configured under the system and used globally. |
3.2.16.2. AAA Management
The config>system>security>password>authentication-order command sets the authentication, authorization and accounting order for the system, including VPRNs.
The config>system>security>profile command is used for system local user profile configuration and is used for local user authentication and authorization, including VPRNs.
Whether AAA servers are set using the system security command or the aaa remote-servers command in the VPRN, they are used as follows:
- If there is a single server configured under VPRN management AAA, then only the VPRN management AAAs are used.For example, the config>system>security>password>authentication-order lists local, TAC+, and RADIUS, while the VPRN only has a RADIUS server configured, and under system>security both TAC+ and RADIUS are configured. In this case, if a management packet arrives on a VPRN and the destination IP matches a local interface in the VPRN, then SR OS will try local management first, and then RADIUS as configured in the VPRN. The SR OS will not try the system>security AAA servers since there is an AAA server configured in VPRN.
- If there is no AAA server configured under VPRN management AAA, then the system AAA servers configured in system>security are used.
3.2.17. Traffic Leaking to GRT
When a management packet arrives on a VPRN, there is a lookup for the destination IP address of the packet. If the destination IP is resolved using VPRN and the corresponding protocol is enabled under VPRN management, then the packet is extracted to CPM.
If the destination IP address is not a VRF IP and GRT leaking is enabled, a second lookup is done in the GRT FIB. If the IP belongs to a local interface in GRT and enable-management is enabled under grt-leaking, then the packet is extracted using GRT leaking to the CPM.
Traffic leaking to Global Route Table (GRT) for the 7750 SR and 7950 XRS allows service providers to offer VPRN and Internet services to their customers over a single VRF interface. This currently supports IPv4 and, for the 7750 SR, requires the customer VPRN interfaces to terminate on a minimum of IOM3-XP and IMM hardware. It is also supported on the 7750 SR-c12.
Packets entering a local VRF interface can have route processing results derived from the VPRN forwarding table or the GRT. The leaking and preferred lookup results are configured on a per VPRN basis. Configuration options can be general (for example, any lookup miss in the VPRN forwarding table can be resolved in the GRT), or specific (for example, specific route(s) should only be looked up in the GRT and ignored in the VPRN). In order to provide operational simplicity and improve streamlining, the CLI configuration is all contained within the context of the VPRN service.
This feature is enabled within the VPRN service context under config>service>vprn>grt-lookup. This is an administrative context and provides the container under which all specific commands can be entered, except for policy definition. Policy definitions remain unchanged but are referenced from this context.
The enable-grt command establishes the basic functionality. When it is configured, any lookup miss in the VRF table will be resolved in the GRT, if available. By itself, this only provides part of the solution. Packet forwarding within GRT must understand how to route packets back to the proper node and to the specific VPRN from which the destination exists. Destination prefixes must be leaked from the VPRN to the GRT through the use of policy. Policies are created under the config>router>policy-options hierarchy. By default, the number of prefixes leaked from the VPRN to the GRT is limited to five. The export-limit command under the grt-lookup hierarchy allows the service provider to override the default, or remove the limit.
When a VPRN forwarding table consists of a default route or an aggregate route, the customer may require the service provider to poke holes in those, or provide more specific route resolution in the GRT. In this case, the service provider may configure a static-route-entry and specify the GRT as the nexthop type.
The lookup result will prefer any successful lookup in the GRT that is equal to or more specific than the static route, bypassing any successful lookup in the local VPRN.
This feature and Unicast Reverse Path Forwarding (uRPF) are mutually exclusive. When a VPRN service is configured with either of these functions, the other cannot be enabled. Also, prefixes leaked from any VPRN should never conflict with prefixes leaked from any other VPRN or existing prefixes in the GRT. Prefixes should be globally unique with the service provider network and if these are propagated outside of a single providers network, they must be from the public IP space and globally unique. Network Address Translation (NAT) is not supported as part of this feature. The following type of routes will not be leaked from VPRN into the Global Routing Table (GRT):
- Aggregate routes
- Blackhole routes
- BGP VPN extranet routes
3.2.18. Traffic Leaking from VPRN to GRT for IPv6
This feature allows IPv6 destination lookups in two distinct routing tables and applies only to the 7750 SR and 7950 XRS. IPv6 packets within a Virtual Private Routed Network (VPRN) service is able to perform a lookup for IPv6 destination against the Global Route Table (GRT) as well as within the local VPRN.
Currently, VPRN to VPRN routing exchange is accomplished through the use of import and export policies based on Route Targets (RTs), the creation of extranets. This new feature allows the use of a single VPRN interface for both corporate VPRN routing and other services (for example, Internet) that are reachable outside the local routing context. This feature takes advantage of the dual lookup capabilities in two separate routing tables in parallel.
This feature enables IPv6 capability in addition to the existing IPv4 VPRN-to-GRT Route Leaking feature.
3.2.19. RIP Metric Propagation in VPRNs
When RIP is used as the PE-CE protocol for VPRNs (IP-VPNs), the RIP metric is only used by the local node running RIP with the Customer Equipment (CE). The metric is not used to or encoded into and MP-BGP path attributes exchanged between PE routers.
The RIP metric can also be used to be exchanged between PE routers so if a customer network is dual homed to separate PEs the RIP metric learned from the CE router can be used to choose the best route to the destination subnet. By using the learned RIP metric to set the BGP MED attribute, remote PEs can choose the lowest MED and in turn the PE with the lowest advertised RIP metric as the preferred egress point for the VPRN. Figure 25 shows RIP metric propagation in VPRNs.
Figure 25: RIP Metric Propagation in VPRNs
3.2.20. NTP Within a VPRN Service
Communication to external NTP clocks through VPRNs is supported in two ways: communication with external servers and peers, and communication with external clients.
Communication with external servers and peers are controlled using the same commands as used for access via base routing (see Network Time Protocol (NTP) in the 7450 ESS, 7750 SR, 7950 XRS, and VSR Basic System Configuration Guide). Communication with external clients is controlled via the VPRN routing configuration. The support for the external clients can be as unicast or broadcast service. In addition, authentication keys for external clients are configurable on a per-VPRN basis.
Only a single instance of NTP remains in the node that is time sourced to as many as five NTP servers attached to the base or management network.
The NTP show command displays NTP servers and all known clients. Because NTP is UDP-based only, no state is maintained. As a result, the show command output only displays when the last message from the client was received.
3.2.21. PTP Within a VPRN Service
The PTP within a VPRN service provides access to the PTP clock within the 7750 SR through one or more VPRN services. Only one VPRN or the base routing instance may have configured peers, but all may have discovered peers. If desired, a limit on the maximum number of dynamic peers allowed may be configured on a per routing instance basis.
For more detail on PTP see the 7450 ESS, 7750 SR, 7950 XRS, and VSR Basic System Configuration Guide.
3.2.22. VPN Route Label Allocation
The method used for allocating a label value to an originated VPN-IP route (exported from a VPRN) depends on the configuration of the VPRN service and its VRF export policies. SR OS supports three 3 label modes:
- label per VRF
- label per next hop (LPN)
- label per prefix (LPP)
Label per VRF is the label allocation default. It is used when the label mode is configured as VRF (or not configured) and the VRF export policies do not apply an advertise-label per-prefix action. All routes exported from the VPRN with the per-VRF label have the same label value. When the PE receives a terminating MPLS packet with a per-VRF label, the label value selects the VRF context in which to perform a forwarding table lookup and this lookup determines the outgoing interface (or set of interfaces if ECMP applies).
Label per next hop is used when the exported route is not a local or aggregate route, the label mode is configured as next-hop, and the VRF export policies do not apply an advertise-label per-prefix override. It is also used when an inactive (backup path) BGP route is exported by effect of the export-inactive-bgp command if there is no advertise-label per-prefix override. All LPN-exported routes with the same primary next hop have the same per-next-hop label value. When the PE receives a terminating MPLS packet with a per-next-hop label, the label lookup selects the outgoing interface for forwarding, without any FIB lookup that might cause problems with overlapping prefixes. LPN does not support ECMP, BGP fast reroute, QPPB, or policy accounting features that might otherwise apply.
Label per-prefix is used when a qualifying IP route is exported by matching a VRF export policy action with advertise-label per-prefix. Any IPv4 or IPv6 route that is not a local route, aggregate route, BGP-VPN route, or GRT lookup static route qualifies. With LPP, every prefix is associated with its own unique label value that does not change while the route is present in the route table. When the PE receives a terminating MPLS packet with a per-prefix label value, the packet is forwarded as if the FIB lookup found only the matching prefix route and not any of the more specific prefix routes that would normally be selected. LPP supports ECMP, QPPB, and policy accounting as part of the egress forwarding decision. It does not support BGP fast reroute or BGP sticky ECMP.
The following points summarize the logic that determines the label allocation method for an exported route:
- If the IP route is LOCAL, AGGREGATE, or BGP-VPN always use the VRF label.
- If the IP route is accepted by a VRF export policy with the advertise-label per-prefix action, use LPP.
- If the IP (BGP) route is exported by the export-inactive-bgp command (VPRN best external), use LPN.
- If the IP route is exported by a VPRN configured for label-mode next-hop, use LPN.
- Else, use the per-VRF label.
3.2.22.1. Configuring the Service Label Mode
To change the service label mode of the VPRN for the 7750 SR, the config>service>vprn>label-mode {vrf | next-hop} command is used:
The default mode (if the command is not present in the VPRN configuration) is vrf meaning distribution of one service label for all routes of the VPRN. When a VPRN X is configured with the label-mode next-hop command the service label that it distributes with an IPv4 or IPv6 route that it exports depends on the type of route as summarized in Table 34.
Table 34: Service Labels Distributed in Service Label per Next-Hop Mode
Route Type | Distributed Service Label |
remote route with IP A (associated with a SAP) as resolved next-hop | platform-wide unique label allocated to next-hop A |
remote route with IP B (associated with a spoke SDP) as resolved next-hop | platform-wide unique label allocated to next-hop B |
local route | platform-wide unique label allocated to VPRN X |
aggregate route | platform-wide unique label allocated to VPRN X |
ECMP route | platform-wide unique label allocated to next-hop A (the lowest next-hop address in the ECMP set) |
BGP route with a backup next-hop (BGP FRR) | platform-wide unique label allocated to next-hop A (the lowest next-hop address of the primary next-hops) |
A change to the label-mode of a VPRN requires the VPRN to first be shutdown.
3.2.22.2. Restrictions and Usage Notes
The service label per next-hop mode has the following restrictions (applies only to the 7750 SR):
- ECMP — The VPRN label mode should be set to VRF if distribution of traffic across the multiple PE-CE next-hop interfaces of an ECMP route is desired.
- Hub and spoke VPN — The VPRN label mode should not be set to next-hop if the operator does not want the hub-connected CE to be involved in the forwarding of spoke-to-spoke traffic.
- BGP next-hop indirection — BGP next-hop indirection has no benefit in service label per next-hop mode. When the resolved next-hop interface of a BGP next-hop changes all of the affected BGP routes must be re-advertised to VPRN peers with the new service label corresponding to the new resolved next-hop.
- BGP anycast — When a PE failure results in redirection of MPLS packets to the other PE in a dual-homed pair, the service label mode is forced to VRF, for example, FIB lookup will determine the next-hop even if the label mode of the VPRN is configured as next-hop.
- U-turn routing — U-turn routing is effectively disabled by service-label per next-hop.
- Carrier Supporting Carrier — The label-mode configuration of a VPRN with CSC interfaces is ignored for BGP-3107 routes learned from connected CSC-CE devices.
3.2.23. VPRN Support for BGP Flowspec
When a VPRN BGP instance receives an IPv4 or IPv6 flow route, and that route is valid/best, the system attempts to construct an IPv4 or IPv6 filter entry from the NLRI contents and the actions encoded in the UPDATE message. If the attempt is successful, the filter entry is added to the system-created “fSpec-n” IPv4 or IPv6 embedded filter, where n is the service-id of the VPRN. These embedded filters may be inserted into configured IPv4 and IPv6 filter policies that are applied to ingress traffic on a selected set of the VPRN’s IP interfaces. These interfaces can include SAP and spoke SDP interfaces, but not CsC network interfaces.
When flowspec rules are embedded into a user-defined filter policy, the insertion point of the rules is configurable through the offset parameter of the embed-filter command. The sum of the ip-filter-max-size and offset must not exceed the maximum filter entry-id range.
3.2.24. MPLS Entropy Label and Hash Label
The router supports both the MPLS entropy label (RFC 6790) and the Flow Aware Transport label, known as the hash label (RFC 6391). These labels allow LSR nodes in a network to load-balance labeled packets in a much more granular fashion than allowed by simply hashing on the standard label stack. See the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide for further information.
3.2.25. LSP Tagging for BGP Next-Hops or Prefixes and BGP-LU
It is possible to constrain the tunnels used by the system for resolution of BGP next-hops or prefixes and BGP labeled unicast routes using LSP administrative tags. Refer to “LSP Tagging and Auto-Bind Using Tag Information“ section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide for more information.
3.2.26. Route Leaking from the Global Route Table to VPRN Instances
The Global Route Table (GRT) to VPRN route leaking feature allows actual routes from the global route table to be exported into specific VPRN instances allowing those routes to be used for forwarding as well as being re-advertised within the VPRN context.
There are two stages for route leaking. The first stage requires the configuration of a set of leak-export route policies that identifies which GRT routes are subject to being exported into VPRN services. The configure>router>leak-export command is used to configure between one and four route policies. The GRT routes must match those policy entries that are configured with action accept. In addition, the configure>router>leak-export-limit command is used to specify the maximum number of GRT routes that can be included in the GRT leak pool.
The second stage requires the configuration of an import-grt policy that specifies which routes within the GRT leak pool that are leaked into the associated VPRN instances route table. The config>service>vprn>grt-lookup>import-grt command is used and accepts one route policy. In order for the GRT route to be leaked into the local VPRN, the route must match a policy entry with action accept.
If a GRT route passes both stages it is added into the VPRN route table which it to be used for IP forwarding as well as re-advertisement within other routing protocols within the VPRN context.
Both IPv4 and IPv6 routes can be leaked using this process from the GRT into one or more VPRN instances. The GRT route types that can be leaked using this process are:
- RIP, OSPF and IS-IS routes
- Direct routes
- Static routes
3.3. QoS on Ingress Bindings
Traffic is tunneled between VPRN service instances on different PEs over service tunnels bound to MPLS LSPs or GRE tunnels. The binding of the service tunnels to the underlying transport is achieved either automatically (using the auto-bind-tunnel command) or statically (using the spoke-sdp command; not that under the VPRN IP interface). QoS control can be applied to the service tunnels for traffic ingressing into a VPRN service; see Figure 26.
Figure 26: Ingress QoS Control on VPRN Bindings
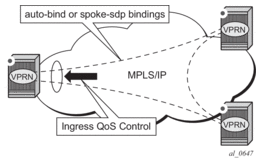
An ingress queue group must be configured and applied to the ingress network FP where the traffic is received for the VPRN. All traffic received on that FP for any binding in the VPRN (either automatically or statically configured) which is redirected to a policer in the FP queue group (using fp-redirect-group in the network QoS policy) will be controlled by that policer. As a result, the traffic from all such bindings is treated as a single entity (per forwarding class) with regard to ingress QoS control. Any fp-redirect-group mcast-policer, broadcast-policer or unknown-policer commands in the network QoS policy are ignored for this traffic (IP multicast traffic would use the ingress network queues or queue group related to the network interface).
Ingress classification is based on the configuration of the ingress section of the specified network QoS policy, noting that the dot1p and exp classification is based on the outer Ethernet header and MPLS label whereas the DSCP applies to the outer IP header if the tunnel encapsulation is GRE, or the DSCP in the first IP header in the payload if ler-use-dscp is enabled in the ingress section of the referenced network QoS policy.
Ingress bandwidth control does not take into account the outer Ethernet header, the MPLS labels/control word or GRE headers, or the FCS of the incoming frame.
The following command configures the association of the network QoS policy and the FP queue group and instance within the network ingress of a VPRN:
When this command is configured, it overrides the QoS applied to the related network interfaces for unicast traffic arriving on bindings in that VPRN. The IP and IPv6 criteria statements are not supported in the applied network QoS policy.
This is supported for all available transport tunnel types and is independent of the label mode (vrf or next-hop) used within the VPRN. It is also supported for Carrier-Supporting-Carrier VPRNs.
The ingress network interfaces on which the traffic is received must be on FP2- and higher-based hardware.
3.4. Multicast in IP-VPN Applications
This section and its subsections focuses on Multicast in IP VPN functionality. Refer to the 7450 ESS, 7750 SR, 7950 XRS, and VSR Multicast Routing Protocols Guide for information about multicast protocols.
Applications for this feature include enterprise customer implementing a VPRN solution for their WAN networking needs, customer applications including stock-ticker information, financial institutions for stock and other types of trading data and video delivery systems.
Implementation of multicast in IP VPNs entails the support and separation of the providers core multicast domain from the various customer multicast domains and the various customer multicast domains from each other.
Figure 27: Multicast in IP-VPN Applications
Figure 27 depicts an example of multicast in an IP-VPN application. The provider’s domain encompasses the core routers (1 through 4) and the edge routers (5 through 10). The various IP-VPN customers each have their own multicast domain, VPN-1 (CE routers 12, 13 and 16) and VPN-2 (CE Routers 11, 14, 15, 17 and 18). Multicast in this VPRN example, the VPN-1 data generated by the customer behind router 16 will be multicast only by PE 9 to PE routers 6 and 7 for delivery to CE routers 12 and 13 respectively. Data generated for VPN-2 generated by the customer behind router 15 will be forwarded by PE 8 to PE routers 5, 7 and 10 for delivery to CE routers 18, 11, 14 and 17 respectively.
The demarcation of these domains is in the PE’s (routers 5 through 10). The PE router participates in both the customer multicast domain and the provider’s multicast domain. The customer’s CEs are limited to a multicast adjacency with the multicast instance on the PE specifically created to support that specific customer’s IP-VPN. This way, customers are isolated from the provider’s core multicast domain and other customer multicast domains while the provider’s core routers only participate in the provider’s multicast domain and are isolated from all customers’ multicast domains.
The PE for a given customer’s multicast domain becomes adjacent to the CE routers attached to that PE and to all other PE’s that participate in the IP-VPN (or customer) multicast domain. This is achieved by the PE who encapsulates the customer multicast control data and multicast streams inside the provider’s multicast packets. These encapsulated packets are forwarded only to the PE nodes that are attached to the same customer’s edge routers as the originating stream and are part of the same customer VPRN. This prunes the distribution of the multicast control and data traffic to the PEs that participate in the customer’s multicast domain. The Rosen draft refers to this as the default multicast domain for this multicast domain; the multicast domain is associated with a unique multicast group address within the provider’s network.
3.4.1. Use of Data MDTs
Using the above method, all multicast data offered by a given CE is always delivered to all other CEs that are part of the same multicast. It is possible that a number of CEs do not require the delivery of a particular multicast stream because they have no downstream receivers for a specific multicast group. At low traffic volumes, the impact of this is limited. However, at high data rates this could be optimized by devising a mechanism to prune PEs from the distribution tree that although forming part of the customer multicast have no need to deliver a given multicast stream to the CE attached to them. To facilitate this optimization, the Rosen draft specifies the use of data MDTs. These data MDTs are signaled once the bandwidth for a given SG exceeds the configurable threshold.
Once a PE detects it is transmitting data for the SG in excess of this threshold, it sends an MDT join TLV (at 60 second intervals) over the default MDT to all PEs. All PEs that require the SG specified in the MDT join TLV will join the data MDT that will be used by the transmitting PE to send the given SG. PEs that do not require the SG will not join the data MDT, thus pruning the multicast distribution tree to just the PEs requiring the SG. After providing sufficient time for all PEs to join the data MDT, the transmitting PE switches the given multicast stream to the data MDT.
PEs that do not require the SG to be delivered, keep state to allow them to join the data MDT as required.
When the bandwidth requirement no longer exceeds the threshold, the PE stops announcing the MDT join TLV. At this point the PEs using the data MDT will leave this group and transmission resumes over the default MDT.
Sampling to check if an s,g has exceeded the threshold occurs every ten seconds. If the rate has exceeded the configured rate in that sample period then the data MDT is created. If during that period the transmission rate has not exceeded the configured threshold then the data MDT is not created. If the data MDT is active and the transmission rate in the last sample period has not exceeded the configured rate then the data MDT is torn down and the multicast stream resumes transmission over the default MDT.
3.4.2. Multicast Protocols Supported in the Provider Network
When MVPN auto-discovery is disabled, PIM-SM can be used for I-PMSI, and PIM-SSM or PIM-SM (Draft-Rosen Data MDT) can be used for S-PMSI; When MVPN S-PMSI auto-discovery is enabled, both PIM-SM and PIM SSM can be used for I-PMSI, and PIM-SSM can be used for S-PMSI. In the customer network, both PIM-SM and PIM-SSM are supported.
An MVPN is defined by two sets of sites: sender sites set and receiver sites set, with the following properties:
- Hosts within the sender sites set could originate multicast traffic for receivers in the receiver sites set.
- Receivers not in the receiver sites set should not be able to receive this traffic.
- Hosts within the receiver sites set could receive multicast traffic originated by any host in the sender sites set.
- Hosts within the receiver sites set should not be able to receive multicast traffic originated by any host that is not in the sender sites set.
A site could be both in the sender sites set and receiver sites set, which implies that hosts within such a site could both originate and receive multicast traffic. An extreme case is when the sender sites set is the same as the receiver sites set, in which case all sites could originate and receive multicast traffic from each other.
Sites within a given MVPN may be either within the same, or in different organizations, which implies that an MVPN can be either an intranet or an extranet. A given site may be in more than one MVPN, which implies that MVPNs may overlap. Not all sites of a given MVPN have to be connected to the same service provider, which implies that an MVPN can span multiple service providers.
Another way to look at MVPN is to say that an MVPN is defined by a set of administrative policies. Such policies determine both sender sites set and receiver site set. Such policies are established by MVPN customers, but implemented by MVPN service providers using the existing BGP/MPLS VPN mechanisms, such as route targets, with extensions, as necessary.
3.4.3. MVPN Membership Auto-discovery using BGP
BGP-based auto-discovery is performed by a multicast VPN address family. Any PE that attaches to an MVPN must issue a BGP update message containing an NLRI in this address family, along with a specific set of attributes.
The PE router uses route targets to specify MVPN route import and export. The route target may be the same as the one used for the corresponding unicast VPN, or it may be different. The PE router can specify separate import route targets for sender sites and receiver sites for a given MVPN.
The route distinguisher (RD) that is used for the corresponding unicast VPN can also be used for the MVPN.
When BGP auto-discovery is enabled, PIM peering on the I-PMSI is disabled, so no PIM hellos are sent on the I-PMSI. C-trees to P-tunnels bindings are also discovered using BGP S-PMSI AD routes, instead of PIM join TLVs. Configure PIM join TLVs when c-mcast-signaling is set to pim in the config>service>vprn>mvpn>provider-tunnel>selective>auto-discovery-disable context.
Table 35 and Table 36 describe the supported configuration combinations. If the CLI combination is not allowed, the system returns an error message. If the CLI command is marked as “ignored” in the table, the configuration is not blocked, but its value is ignored by the software.
Table 35: Supported Configuration Combinations
Auto-Discovery | Inclusive PIM SSM | Action |
Yes | Yes | Allowed |
MDT-SAFI | Yes | Allowed |
No | Yes | Not Allowed |
Yes or No | No | Allowed |
MDT-SAFI | No | Ignored |
MDT-SAFI | No (RSVP and MLDP) | Not Allowed |
Table 36: Supported Configuration Combinations
Auto-Discovery | C-Mcast-Signaling | s-PMSI Auto-Discovery | Action |
Yes | BGP | Ignored | Allowed |
Yes | PIM | Yes | Allowed |
Yes | PIM | No | Allowed |
No | BGP | Ignored | Not Allowed |
No | PIM | Ignored | Allowed |
MDT-SAFI | Ignored (PIM behavior) | Ignored (“No” behavior) | Allowed |
For example, if auto-discovery is disabled, the c-mcast-signaling bgp command will fail with an error message stating:
C-multicast signaling in BGP requires auto-discovery to be enabled
If c-mcast-signaling is set to bgp then no auto-discovery will fail with an error message stating
C-multicast signaling in BGP requires auto-discovery to be enabled
When c-mcast-signaling is set to bgp, S-PMSI A-D is always enabled (its configuration is ignored);
When auto-discovery is disabled, S-PMSI A-D is always disabled (its configuration is ignored).
When auto-discovery is enabled and c-multicast-signaling is set to pim, the S-PMSI A-D configuration value is used.
mdt-safi uses pim c-mcast-signaling and s-pmsi-signaling regardless of what is configured. A c-mcast-signaling or s-pmsi-signaling configuration is ignored, but both pim and bgp values are allowed.
mdt-safi is only applicable to PIM-SSM I-PMSI. PIM-SM (ASM) I-PMSI is configurable but is ignored. RSVP and MLDP I-PMSI are not allowed.
MVPN implementation based on RFC 6037, Cisco Systems’ Solution for Multicast in MPLS/BGP IP VPNs can support membership auto-discovery using BGP MDT-SAFI. A CLI option is provided per MVPN instance to enable auto-discovery either using BGP MDT-SAFI or NG-MVPN. Only PIM-MDT is supported with BGP MDT-SAFI method.
3.4.4. PE-PE Transmission of C-Multicast Routing using BGP
MVPN c-multicast routing information is exchanged between PEs by using c-multicast routes that are carried using MCAST-VPN NLRI.
3.4.5. VRF Route Import Extended Community
VRF route import is an IP address-specific extended community, of an extended type, and is transitive across AS boundaries (RFC 4360, BGP Extended Communities Attribute).
To support MVPN, in addition to the import/export route target extended communities used by the unicast routing, each VRF on a PE must have an import route target extended community that controls imports of C-multicast routes into a particular VRF.
The c-multicast import RT uniquely identifies a VRF, and is constructed as follows:
- The Global Administrator field of the c-multicast import RT must be set to an IP address of the PE. This address should be common for all the VRFs on the PE (this address may be the PE’s loopback address).
- The Local Administrator field of the c-multicast import RT associated with a given VRF contains a 2 octets long number that uniquely identifies that VRF within the PE that contains the VRF.
A PE that has sites of a given MVPN connected to it communicates the value of the c-multicast import RT associated with the VRF of that MVPN on the PE to all other PEs that have sites of that MVPN. To accomplish this, a PE that originates a (unicast) route to VPN-IP addresses includes in the BGP updates message that carries this route the VRF route import extended community that has the value of the c-multicast import RT of the VRF associated with the route, except if it is known a priori that none of these addresses will act as multicast sources and/or RP, in which case the (unicast) route need not carry the VRF Route Import extended community.
All c-multicast routes with the c-multicast import RT specific to the VRF must be accepted. In this release, vrf-import and vrftraget policies don’t apply to C-multicast routes.
The decision flow path is shown below.
if (route-type == c-mcast-route)
if (route_target_list includes C-multicast_Import_RT){
else
drop;
else
Run vrf_import and/or vrf-target;
3.4.6. Provider Tunnel Support
3.4.6.1. Point-to-Multipoint Inclusive (I-PMSI) and Selective (S-PMSI) Provider Multicast Service Interface
BGP C-multicast signaling must be enabled for an MVPN instance to use P2MP RSVP-TE or LDP as I-PMSI (equivalent to ‘Default MDT’, as defined in draft Rosen MVPN) and S-PMSI (equivalent to ‘Data MDT’, as defined in draft Rosen MVPN).
By default, all PE nodes participating in an MVPN receive data traffic over I-PMSI. Optionally, (C-*, C-*) wildcard S-PMSI can be used instead of I-PMSI. See section Wildcard (C-*, C-*) P2MP LSP S-PMSI for more information. For efficient data traffic distribution, one or more S-PMSIs can be used, in addition to the default PMSI, to send traffic to PE nodes that have at least one active receiver connected to them. For more information, see P2MP LSP S-PMSI.
Only one unique multicast flow is supported over each P2MP RSVP-TE or P2MP LDP LSP S-PMSI. Number of S-PMSI that can be initiated per MVPN instance is restricted by CLI command maximum-p2mp-spmsi. P2MP LSP S-PMSI cannot be used for more than one (S,G) stream (that is, multiple multicast flow) as number of S-PMSI per MVPN limit is reached. Multicast flows that cannot switch to S-PMSI remain on I-PMSI.
3.4.6.2. P2MP RSVP-TE I-PMSI and S-PMSI
Point-to-Multipoint RSVP-TE LSP as inclusive or selective provider tunnel is available with BGP NG-MVPN only. P2MP RSVP-TE LSP is dynamically setup from root node on auto discovery of leaf PE nodes that are participating in multicast VPN. Each RSVP-TE I-PMSI or S-PMSI LSP can be used with a single MVPN instance only.
RSVP-TE LSP template must be defined (see 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide) and bound to MVPN as inclusive or selective (S-PMSI is for efficient data distribution and is optional) provider tunnel to dynamically initiate P2MP LSP to the leaf PE nodes learned via NG-MVPN auto-discovery signaling. Each P2MP LSP S2L is signaled based on parameters defined in LSP template.
3.4.6.3. P2MP LDP I-PMSI and S-PMSI
Point-to-Multipoint LDP LSP as inclusive or selective provider tunnel is available with BGP NG-MVPN only. P2MP LDP LSP is dynamically setup from leaf nodes on auto discovery of leaf node PE nodes that are participating in multicast VPN. Each LDP I-PMSI or S-PMSI LSP can be used with a single MVPN instance only.
The multicast-traffic CLI command must be configured per LDP interface to enable P2MP LDP setup. P2MP LDP must also be configured as inclusive or selective (S-PMSI is for efficient data distribution and is optional) provider tunnel per MVPN to dynamically initiate P2MP LSP to leaf PE nodes learned via NG-MVPN auto-discovery signaling.
3.4.6.4. Wildcard (C-*, C-*) P2MP LSP S-PMSI
Wildcard S-PMSI allows usage of selective tunnel as a default tunnel for a given MVPN. By using wildcard S-PMSI, operators can avoid full mesh of LSPs between MVPN PEs, reducing related signaling, state, and BW consumption for multicast distribution (no traffic is sent to PEs without any receivers active on the default PMSI).
The SR OS allows an operator to configure wildcard S-PMSI for ng-MVPN (config>service>vprn>mvpn>pt>inclusive>wildcard-spmsi), using LDP and RSVP-TE in P-instance. Support includes:
- IPv4 and IPv6
- PIM ASM and SSM
- directly attached receivers
The SR OS (C-*, C-*) wildcard implementation uses wildcard S-PMSI instead of I-PMSI for a given MVPN. To switch MVPN from I-PMSI to (C-*, C-*) S-PMSI a VPRN shutdown is required. ISSU and UMH redundancy can be used to minimize the impact.
To minimize outage, the following upgrade order is recommended:
- Route Reflector
- Receiver PEs
- backup UMH
- active UMH
RSVP-TE/mLDP configuration under inclusive provider tunnel (config>service>vprn>mvpn>pt>inclusive) apply to wildcard S-PMSI when enabled.
Wildcard C-S and C-G values are encoded as defined in RFC6625: using zero for Multicast Source Length and Multicast Group Length and omitting Multicast Source and Multicast Group values respectively in MCAST_VPN_NLRI. For example, a (C-*, C-*) will be advertised as: RD, 0x00, 0x00, and originating router's IP address.
| Note: All SR OSs with BGP peering session to the PE with RFC6625 support enabled must be upgraded to SR OS release 13.0 before the feature is enabled. Failure to do so will result in the following processing on a router with BGP peering session to an RFC6625-enabled PE:
|
The procedures implemented by SR OS are compliant to section 3 and 4 of RFC, 6625. Wildcards encoded as described above are carried in NLRI field of MP_REACH_NLRF_ATTRIBUTE. Both IPv4 and IPv6 are supported: (AFI) of 1 or 2 and a Subsequent AFI (SAFI) of MCAST-VPN.
The (C-*, C-*) S-PMSI is established as follows:
- UMH PEs advertise I-PMSI A-D routes without tunnel information present (empty PTA) - encoded as per RFC6513/6514 prior to advertising wildcard S-PMSI. I-PMSI needs to be signaled and installed on receiver PEs, because (C-*, C-*) S-PMSI is only installed when a first receiver is added. However, no LSP is established for I-PMSI).
- UMH PEs advertise S-PMSI A-D route whose NLRI contains (C-*, C-*) with tunnel information encoded as per RFC 6625.
- Receiver PEs join wildcard S-PMSI if there are any receivers present.
| Note: If UMH PE does not encode I-PMSI/S-PMSI A-D routes as per the above, or advertises both I-PMSI and wildcard S-PMSI with the tunnel information present, no interoperability can be achieved. |
To ensure proper operation of BSR between PEs with (C-*, C-*) S-PMSI signaling, SR OS implements two modes of operations for BSR.
By default (bsr unicast):
- BSR PDUs are sent/forwarded as unicast PDUs to neighbor PEs when I-PMSI with Pseudo-tunnel interface is installed.
- At every BSR interval timer BSR Unicast PDU are sent to all I-PMSI interfaces when this is an elected BSR.
- BSMs received as multicast from C-instance interfaces are flooded as unicast in the P-instance.
- All PEs process BSR PDU's received on I-PMSI Pseudo-tunnel interface as unicast packets.
- BSR PDU's are not forwarded to PE's management control interface.
- BSR unicast PDU's use PE's System IP address as destination IP and sender PE's System address as Source IP.
- The BSR unicast functionality ensures that no special state needs to be created for BSR when (C-*, C-*) S-PMSI is enabled, which is beneficiary considering low volume of BSR traffic.
Note:
|
BSR S-PMSI mode can be enabled to allow interoperability with other vendors. In that mode full mesh S-PMSI is required and created between all PEs in MVPN to exchange BSR PDUs between all PEs in MVPN. To operate as expected, the BSR S-PMSI mode requires a selective P-tunnel configuration. For IPv6 support (including dual-stack) of BSR S-PMSI mode, the IPv6 default system interface address must be configured as a loopback interface address under the VPRN and VPRN PIM contexts. Changing BSR signaling requires a VPRN shutdown.
Other key feature interactions and caveats for (C-*, C-*) include the following:
- Extranet is fully supported with wildcard S-PMSI trees.
- (C-S, C-G) S-PMSIs are supported when (C-*, C-*) S-PMSI is configured (including both BW and receiver PE driven thresholds).
- Geo-redundancy is supported (deploying with geo-redundancy eliminates traffic duplication when geo-redundant source has no active receivers at a cost of slightly increased outage upon a switch since wildcard S-PMSI may need to be re-establish).
- PIM in P-instance is not supported.
- SR OS implementation requires wildcard encoding as per RFC6625 and I-PMSI/S-PMSI signaling as defined above (I-PMSI signaled with empty PTA then S-PMSI signaled with P-tunnel PTA) for interoperability. Implementations that do not adhere to RFC6625 encoding, or signal both I-PMSI and S-PMSI with P-tunnel PTA will not inter-operate with SR OS implementation).
3.4.6.5. P2MP LSP S-PMSI
NG-MVPN support P2MP RSVP-TE and P2MP LDP LSPs as selective provider multicast service interface (S-PMSI). S-PMSI is used to avoid sending traffic to PEs that participate in multicast VPN, but do not have any receivers for a given C-multicast flow. This allows more-BW efficient distribution of multicast traffic over the provider network, especially for high bandwidth multicast flows. S-PMSI is spawned dynamically based on configured triggers as described in S-PMSI trigger thresholds section.
In MVPN, the head-end PE firstly discovers all the leaf PEs via I-PMSI A-D routes. It then signals the P2MP LSP to all the leaf PEs using RSVP-TE. In the scenario of S-PMSI:
- The head-end PE sends an S-PMSI A-D route for a specific C-flow with the Leaf Information Required bit set.
- The PEs who are interested in the C-flow respond with Leaf A-D routes.
- The head-end PE then signals the P2MP LSP to all the leaf PEs using RSVP-TE.
Also, because the receivers may come and go, the implementation supports dynamically adding and pruning leaf nodes to and from the P2MP LSP.
When the tunnel type in the PMSI attribute is set to RSVP-TE P2MP LSP, the tunnel identifier is <Extended Tunnel ID, Reserved, Tunnel ID, P2MP ID>, as carried in the RSVP-TE P2MP LSP SESSION Object.
The PE can also learn via an A-D route that it needs to receive traffic on a particular RSVP-TE P2MP LSP before the LSP is actually setup. In this case, the PE needs to wait until the LSP is operational before it can modify its forwarding tables as directed by the A-D route.
Because of the way that LDP normally works, mLDP P2MP LSPs are setup without solicitation from the leaf PEs towards the head-end PE. The leaf PE discovers the head-end PE via I-PMSI or S-PMSI A-D routes. The tunnel identifier carried in the PMSI attribute is used as the P2MP FEC element. The tunnel identifier consists of the head-end PE’s address, along with a Generic LSP identifier value. The Generic LSP identifier value is automatically generated by the head-end PE.
3.4.6.6. Dynamic Multicast Signaling over P2MP LDP in VRF
This feature provides a multicast signaling solution for IP-VPNs, allowing the connection of IP multicast sources and receivers in C-instances, which are running PIM multicast protocol using Rosen MVPN with BGP SAFI and P2MP mLDP in P-instance. The solution dynamically maps each PIM multicast flow to a P2MP LDP LSP on the source and receiver PEs.
The feature uses procedures defined in RFC 7246: Multipoint Label Distribution Protocol In-Band Signaling in Virtual Routing and Forwarding (VRF) Table Context. On the receiver PE, PIM signaling is dynamically mapped to the P2MP LDP tree setup. On the source PE, signaling is handed back from the P2MP mLDP to the PIM. Due to dynamic mapping of multicast IP flow to P2MP LSP, provisioning and maintenance overhead is eliminated as multicast distribution services are added and removed from the VRF. Per (C-S, C-G) IP multicast state is also removed from the network, since P2MP LSPs are used to transport multicast flows.
Figure 28 illustrates dynamic mLDP signaling for IP multicast in VPRN.
Figure 28: Dynamic mLDP Signaling for IP Multicast in VPRN
As illustrated in Figure 28, P2MP LDP LSP signaling is initiated from the receiver PE that receives PIM JOIN from a downstream router (Router A). To enable dynamic multicast signaling, the p2mp-ldp-tree-join must be configured on PIM customer-facing interfaces for the given VPRN of Router A. This enables handover of multicast tree signaling from the PIM to the P2MP LDP LSP. Being a leaf node of the P2MP LDP LSP, Router A selects the upstream-hop as the root node of P2MP LDP FEC, based on a routing table lookup. If an ECMP path is available for a given route, then the number of trees are equally balanced towards multiple root nodes. The PIM joins are carried in the Transit Source PE (Router B), and multicast tree signaling is handed back to the PIM and propagated upstream as native-IP PIM JOIN toward C-instance multicast source.
The feature is supported with IPv4 and IPv6 PIM SSM and IPv4 mLDP. Directly connected IGMP/MLD receivers are also supported, with PIM enabled on outgoing interfaces and SSM mapping configured, if required.
The following are feature caveats:
- Dynamic mLDP signaling in a VPRN instance is mutually exclusive with Rosen or NG-MVPN.
- A single instance of P2MP LDP LSP is supported between the receiver PE and Source PE per multicast flow; there is no stitching of dynamic trees.
- Extranet functionality is not supported.
- The router LSA link ID or the advertising router ID must be a routable IPv4 address (including IPv6 into IPv4 mLDP use cases).
- IPv6 PIM with dynamic IPv4 mLDP signaling is not supported with e-BGP or i-BGP with IPv6 next-hop.
- Inter-AS and IGP inter-area scenarios where the originating router is altered at the ASBR and ABR respectively, (hence PIM has no way to create the LDP LSP towards the source), are not supported.
- When dynamic mLDP signaling is deployed, a change in Route Distinguisher (RD) on the Source PE is not acted upon for any (C-S, C-G)s until the receiver PEs learn about the new RD (via BGP) and send explicit delete and create with the new RD.
- Procedures of Section 2 of RFC 7246 for a case where UMH and the upstream PE do not have the same IP address are not supported.
3.4.6.7. MVPN Sender-only/Receiver-only
In multicast MVPN, by default, if multiple PE nodes form a peering with a common MVPN instance then each PE node originates a multicast tree locally towards the remaining PE nodes that are member of this MVPN instance. This behavior creates a mesh of I-PMSI across all PE nodes in the MVPN. It is often a case, that a given VPN has many sites that will host multicast receivers, but only few sites that either host both receivers and sources or sources only.
MVPN Sender-only/Receiver-only allows optimization of control and data plane resources by preventing unnecessary I-PMSI mesh when a given PE hosts multicast sources only or multicast receivers only for a given MVPN.
For PE nodes that host only multicast sources for a given VPN, operators can now block those PEs, through configuration, from joining I-PMSIs from other PEs in this MVPN. For PE nodes that host only multicast receivers for a given VPN, operators can now block those PEs, through configuration, to set-up a local I-PMSI to other PEs in this MVPN.
MVPN Sender-only/Receiver-only is supported with ng-MVPN using IPv4 RSVP-TE or IPv4 LDP provider tunnels for both IPv4 and IPv6 customer multicast. Figure 29 depicts 4-site MVPN with sender-only, receiver-only and sender-receiver (default) sites.
Figure 29: MVPN Sender-only/Receiver-only Example
Extra attention needs to be paid to BSR/RP placement when Sender-only/Receiver-only is enabled. Source DR sends unicast encapsulated traffic towards RP, therefore, RP shall be at sender-receiver or sender-only site, so that *G traffic can be sent over the tunnel. BSR shall be deployed at the sender-receiver site. BSR can be at sender-only site if the RPs are at the same site. BSR needs to receive packets from other candidate-BSR and candidate-RPs and also needs to send BSM packets to everyone.
3.4.6.8. S-PMSI Trigger Thresholds
The mLDP and RSVP-TE S-PMSIs support two types of data thresholds: bandwidth-driven and receiver-PE-driven. The threshold evaluation and bandwidth driven threshold functionality are described in Use of Data MDTs.
In addition to the bandwidth threshold functionality, an operator can enable receiver-PE-driven threshold behavior. Receiver PE thresholds ensure that S-PMSI is only created when BW savings in P-instance justify extra signaling required to establish a new S-PMSI. For example, the number of receiver PEs interested in a given C-multicast flow is meaningfully smaller than the number of receiver PEs for default PMSI (I-PMSI or wildcard S-PMSI). To ensure that S-PMSI is not constantly created/deleted, two thresholds need to be specified: receiver PE add threshold and receiver PE delete threshold (expected to be significantly higher).
When a (C-S, C-G) crosses a data threshold to create S-PMSI, instead of regular S-PMSI signaling, sender PE originates S-PMSI explicit tracking procedures to detect how many receiver PEs are interested in a given (C-S, C-G). When receiver PEs receive an explicit tracking request, each receiver PE responds, indicating whether there are multicast receivers present for that (C-S, C-G) on the given PE (PE is interested in a given (C-S, C-G)). If the geo-redundancy feature is enabled, receiver PEs do not respond to explicit tracking requests for suppressed sources and therefore only Receiver PEs with an active join are counted against the configured thresholds on Source PEs.
Upon regular sampling and check interval, if the previous check interval had a non-zero receiver PE count (one interval delay to not trigger S-PMSI prematurely) and current count of receiver PEs interested in the given (C-S, C-G) is non-zero and is less than the configured receiver PE add threshold, Source PE will set-up S-PMSI for this (C-S, C-G) following standard ng-MVPN procedures augmented with explicit tracking for S-PMSI being established.
Data threshold timer should be set to ensure enough time is given for explicit tracking to complete (for example, setting the timer to value that is too low may create S-PMSI prematurely).
Upon regular data-delay-interval expiry processing, when BW threshold validity is being checked, a current receiver PE count is also checked (for example, explicit tracking continues on the established S-PMSI). If BW threshold no longer applies or the receiver PEs exceed receiver PE delete threshold, the S-PMSI is torn down and (C-S, C-G) joins back the default PMSI.
Changing of thresholds (including enabling disabling the thresholds) is allowed in service. The configuration change is evaluated at the next periodic threshold evaluation.
The explicit tracking procedures follow RFC6513/6514 with clarification and wildcard S-PMSI explicit tracking extensions as described in IETF Draft: draft-dolganow-l3vpn-expl-track-00.
3.4.6.9. Migration from Existing Rosen Implementation
The existing Rosen implementation is compatible to provide an easy migration path.
The following migration procedure are supported:
- Upgrade all the PE nodes that need to support MVPN to the newer release.
- The old configuration will be converted automatically to the new style.
- Node by node, MCAST-VPN address-family for BGP is enabled. Enable auto-discovery using BGP.
- Change PE-to-PE signaling to BGP.
3.4.6.10. Policy-based S-PMSI
SR OS creates a single Selective P-Multicast Service Interface (S-PMSI) per multicast stream: (S,G) or (*,G). To better manage bandwidth allocation in the network, multiple multicast streams are often bundled starting from the same root node into a single, multi-stream S-PMSI. Network bandwidth is usually managed per package or group of packages, rather than per channel.
Multi-stream S-PMSI supports a single S-PMSI for one or more IPv4 (C-S, C-G) or IPv6 (C-S, C-G) streams. Multiple multicast streams starting from the same VPRN going to the same set of leafs can use a single S-PMSI. Multi-stream S-PMSIs can:
- carry exclusively IPv4 or exclusively IPv6, or a mix of channels
- co-exist with a single group S-PMSI
To create a multi-stream S-PMSI, an S-PMSI policy needs to be configured in the VPN context on the source node. This policy maps multiple (C-S, C-G) streams to a single S-PMSI. Because this configuration is done per MVPN, multiple VPNs can have identical policies, each configured for its own VPN context.
When mapping a multicast stream to a multi-stream S-PMSI policy, the data will traverse the S-PMSI without first using the I-PMSI. (Before this feature, when a multicast stream was sourced, the data used the I-PMSI first until a configured threshold was met. After this, if the multicast data exceeded the threshold, it would signal the S-PMSI tunnel and switch from I-PMSI to S-PMSI.)
For multi-stream S-PMSI, if the policy is configured and the multicast data matches the policy rules, the multi-stream S-PMSI is used from the start without using the default I-PMSI.
Multiple multi-stream S-PMSI policies could be assigned to a specific S-PMSI configuration. In this case, the policy acts as a link list. The first (lowest index) that matches the multi-stream S-PMSI policy is used for that specific stream.
The rules for matching a multi-stream S-PMSI on the source node are listed here.
S-PMSI to (C-S, C-G) mapping on Source-PE, in sequence:
- The multi-stream S-PMSI policy is evaluated, starting from the lowest numerical policy index. This allows the feature to be enabled in the service when per-(C-S, C-G) stream configuration is present. Only entries that are not shut down are evaluated. First, the multi-stream S-PMSI (the lowest policy index) that the (C-S, C-G) stream maps to is selected.
- If (C-S, C-G) does not map to any of multi-stream S-PMSIs, per-(C-S, C-G) S-PMSIs are used for transmission if a (C-S, C-G) maps to an existing S-PMSI (based on data-thresholds).
- If S-PMSI cannot be used, the default PMSI is used.
Multi-stream S-PMSI P-tunnel failure handling:
- If an S-PMSI P-tunnel is not available, a default PMSI tunnel is used. When an S-PMSI tunnel fails, all (C-S, C-G) streams using this multi-stream S-PMSI move to the default PMSI. The groups move back to S-PMSI after the S-PMSI tunnel is restored.
3.4.6.10.1. Supported MPLS Tunnels
Multi-stream S-PMSI is configured in the context of an auto-discovery default (that is, NG-MVPN). It supports all existing per-mLDP/RSVP-TE P2MP S-PMSI tunnel functionality for multi-stream S-PMSI LSP templates (RSVP-TE P-instance).
Notes:
- Per-multicast group statistics are not available for multi-stream S-PMSIs on S-PMSI level.
- GRE tunnels are not supported for multi-stream S-PMSI.
3.4.6.10.2. Supported Multicast Features
S-PMSI is supported with PIM ASM and PIM SSM in C-instances.
Notes:
- The multi-stream S-PMSI model uses BSR RP co-located with the source PE or an RP between the source PE and multicast source, that is, upstream of receivers. Both bsr unicast and bsr spmsi can be deployed as applicable.
- The model also supports other RP types.
3.4.6.10.3. In-service Changes to Multi-stream S-PMSI
The operator can change the mapping in service; that is, the operator can move active streams (C-S, C-G) from one S-PMSI to another using the configuration, or from the default PMSI to the S-PMSI, without having to stop data transmission or having to disable a PMSI.
The change is performed by moving a (C-S, C-G) stream from a per-group S-PMSI to a multi-stream S-PMSI and vice versa, and moving a (C-S, C-G) stream from one multi-stream S-PMSI to another multi-stream S-PMSI.
Notes:
- During re-mapping, a changed (C-S, C-G) stream will first be moved to the default PMSI before it is moved to a new S-PMSI, regardless of the type of move. Unchanged (C-S, C-G) streams must remain on an existing PMSIs.
- Any change to a multi-stream S-PMSI policy or to a preferred multi-stream S-PMSI policy (for example, an index change equivalent to less than or equal to the current policy) should be performed during a maintenance window. Failure to perform these types of changes in a maintenance window could potentially cause a traffic outage.
3.4.6.10.4. Configuration Example
In this example, two policies are created on the source node: multi-stream S-PMSI 1 and multi-stream-S-PMSI 10.
A multicast stream with group 224.0.0.x and source 192.0.2.0/24 will map to the first multi-stream policy. The group in the range of 224.0.0.0/24 and source 192.0.2.1/24 will map to policy 10.
3.4.6.11. Policy-based Data MDT
A single data MDT can transport one or more IPv4 (C-S, C-G) streams. This allows multiple multicast streams starting from the same VPRN going to the same set of leafs to utilize a single data MDT. Characteristics of an MDT include:
- a multi-stream data MDT can carry IPv4 only
- a multi-stream data MDT can co-exist with a single-group data MDT
- a default MDT must be configured
To create a multi-stream MDT data, an MDA data policy must be configured in the context of MVPN on the source node. This policy maps multiple (C-S, C-G) streams to a single data MDT. Because this configuration is per MVPN, multiple VPNs can have identical policies configured, each for its own VPN context.
When a multicast stream is mapped to a multi-stream data MDT policy, the data will traverse the default MDT first. The data delay timer is used to switch the data from the default MDT to the multi-stream data MDT.
When the multi-stream data MDT is deleted, the traffic switches back to the default MDT.
In some cases when a new multi-stream data MDT is configured which is better suited, some streams might prefer this new multi-stream data MDT. To switch, the traffic will switch to the default MDT and then to the new multi-stream data MDT.
MDT data can be configured as SSM or ASM.
There can be multiple multi-stream policies assigned to a single data MDT configuration. In this case, the policy acts as a link list, the first (lowest index) matched multi-stream policy is used for that specific stream. The following are the rules of matching a multi-stream data MDT to (C-S, C-G) mapping on a source PE (in order):
- The multi-stream policy is evaluated to enable the feature in service when per-(C-S, C-G) configuration is present, starting from the lowest numerical policy index (only entries that are not shutdown are evaluated). The first multi-stream data MDT (the lowest policy index) the (C-S, C-G) maps to is selected.
- If (C-S, C-G) does not map to any of the multi-stream data MDTs, per-(C-S, C-G) single data MDTs are used if a (C-S, C-G) maps to an existing MDT based on data-thresholds.
- The default MDT is used if no policy matches to a data MDT.
- When a (C-S, C-G) arrives, it start on the default MDT but can switch to a data MDT when the data delay interval expires. It does not check the data-threshold before switching.
- When going from one multi-stream data MDT to a more suitable one, the traffic will first switch to the default MDT and then switch to the new multi-stream data MDT based on the data-delay-interval.
When a data MDT tunnel fails, all (C-S, C-G)s using this multi-stream data MDT move to the default MDT, and the groups move back to the data MDT when it is restored.
3.4.7. MVPN (NG-MVPN) Upstream Multicast Hop Fast Failover
MVPN upstream PE or P node fast failover detection method is supported with RSVP P2MP I-PMSI only. A receiver PE achieves fast upstream failover based on the capability to subscribe multicast flow from multiple UMH nodes and the capability to monitor the health of the upstream PE and intermediate P nodes using an unidirectional multi-point BFD session running over the provider tunnel.
A receiver PE subscribes multicast flow from multiple upstream PE nodes to have active redundant multicast flow available during failure of primary flow. Active redundant multicast flow from standby upstream PE allows instant switchover of multicast flow during failure of primary multicast flow.
Faster detection of multicast flow failure is achieved by keeping track of unidirectional multi-point BFD sessions enabled on the provider tunnel. Multi-point BFD sessions must be configured with 10 ms transmit interval on sender (root) PE to achieve sub-50ms fast failover on receiver (leaf) PE.
UMH tunnel-status selection option must be enabled on the receiver PE for upstream fast failover. Primary and standby upstream PE pairs must be configured on the receiver PE to enable active redundant multicast flow to be received from the standby upstream PE.
3.4.8. Multicast VPN Extranet
Multicast VPN extranet distribution allows multicast traffic to flow across different routing instances. A routing instance that received a PIM/IGMP JOIN but cannot reach source of multicast source directly within its own instance is selected as receiver routing instance (receiver C-instance). A routing instance that has source of multicast stream and accepts PIM/IGMP JOIN from other routing instances is selected as source routing instance (source C-instance). A routing instance that does not have either source or receivers but is used in the core is selected as a transit instance (transit P-instance). The following subsections detail supported functionality.
3.4.8.1. Multicast Extranet for Rosen MVPN for PIM SSM
Multicast extranet is supported for Rosen MVPN with MDT SAFI. Extranet is supported for IPv4 multicast stream for default and data MDTs (PIM and IGMP).
The following extranet cases are supported:
- local replication into a receiver VRF from a source VRF on a source PE
- Transit replication from a source VRF onto a tunnel of a transit core VRF on a source PE. A source VRF can replicate its streams into multiple core VRFs as long as any given stream from source VRF uses a single core VRF (the first tunnel in any core VRF on which a join for the stream arrives). Streams with overlapping group addresses (same group address, different source address) are supported in the same core VRF.
- remote replication from source/transit VRF into one or more receiver VRFs on receiver PEs
- multiple replications from multiple source/transit VRFs into a receiver VRF on receiver PEs
Rosen MVPN extranet requires routing information exchange between the source VRF and the receiver VRF based on route export/import policies:
- Routing information for multicast sources must be exported using an RT export policy from the source VRF instance.
- Routing information must be imported into the receiver/transit VRF instance using an RT import policy.
Caveats:
- The source VRF instance and receiver VRF instance of extranet must exist on a common PE node (to allow local extranet mapping).
- SSM translation is required for IGMP (C-*, C-G).
- An I-PMSI route cannot be imported into multiple VPRNs, and NG-MVPN routes do not need to be imported into multiple VPRNs.
In Figure 30, VPRN-1 is the source VPRN instance and VPRN-2 and VPRN-3 are receiver VPRN instances. The PIM/IGMP JOIN received on VPRN-2 or VPRN-3 is for (S1, G1) multicast flow. Source S1 belongs to VPRN-1. Due to the route export policy in VPRN-1 and the import policy in VPRN-2 and VPRN-3, the receiver host in VPRN-2 or VPRN-3 can subscribe to the stream (S1, G1).
Figure 30: Multicast VPN Traffic Flow
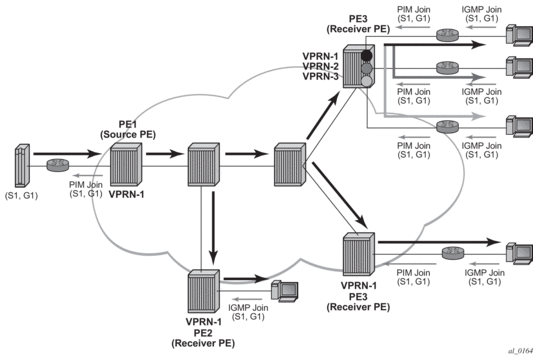
3.4.8.2. Multicast Extranet for NG-MVPN for PIM SSM
Multicast extranet is supported for ng-MVPN with IPv4 RSVP-TE and mLDP I-PMSIs and S-PMSIs including (C-*, C-*) S-PMSI support where applicable. Extranet is supported for IPv4 C-multicast traffic (PIM/IGMP joins).
The following extranet cases are supported:
- local replication into a receiver C-instance MVPN(s) on a source PE from a source P-instance MVPN
- remote replication from P-instance MVPN into one or more receiver C-instance MVPNs on receiver PEs
- multiple replications from multiple source/transit P-instance MVPNs into a receiver C-instance MVPN on receiver PEs
- Transit replication on Source PE is not supported.
Multicast extranet for ng-MVPN, similarly to extranet for Rosen MVPN, requires routing information exchange between source ng-MVPN and receiver ng-MVPN based on route export and import policies. Routing information for multicast sources is exported using an RT export policy from a source ng-MVPN instance and imported into a receiver ng-MVPN instance using an RT import policy. S-PMSI/I-PMSI establishment and C-multicast route exchange occurs in a source ng-MVPN P-instance only (import and export policies are not used for MVPN route exchange). Sender-only functionality must not be enabled for the source/transit ng-MVPN on the receiver PE. It is recommended to enable receiver-only functionality on a receiver ng-MVPN instance.
Caveats:
- Source P-instance MVPN and receiver C-instance MVPN must reside on the receiver PE (to allow local extranet mapping).
- SSM translation is required for IGMP (C-*, C-G).
3.4.8.3. Multicast Extranet with Per-group Mapping for PIM SSM
In some deployments, such as IPTV or wholesale multicast services, it may be desirable to create one or more transit MVPNs to optimize delivery of multicast streams in the provider core. Figure 31 represents a sample deployment model.
Figure 31: Source PE Transit Replication and Receiver PE Per-group SSM Extranet Mapping
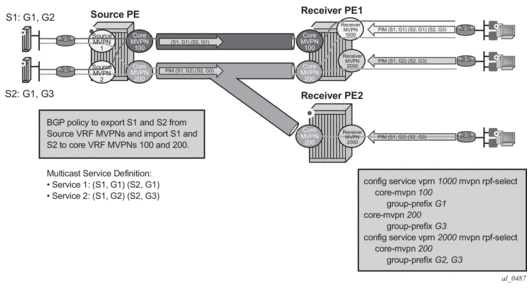
The architecture displayed in Figure 31 requires a source routing instance MVPN to place its multicast streams into one or more transit core routing instance MVPNs (each stream mapping to a single transit core instance only). It also requires receivers within each receiver routing instance MVPN to know which transit core routing instance MVPN they need to join for each of the multicast streams. To achieve this functionality, transit replication from a source routing instance MVPN onto a tunnel of a transit core routing instance MVPN on a source PE (see earlier sub-sections for MVPN topologies supporting transit replication on source PEs) and per-group mapping of multicast groups from receiver routing instance MVPNs to transit core routing instance MVPNs (as defined below) are required.
For per-group mapping on a receiver PE, the operator must configure a receiver routing instance MVPN per-group mapping to one or more source/transit core routing instance MVPNs. The mapping allows propagation of PIM joins received in the receiver routing instance MVPN into the core routing MVPN instance defined by the map. All multicast streams sourced from a single multicast source address are always mapped to a single core routing instance MVPN for a given receiver routing instance MVPN (multiple receiver MVPNs can use different core MVPNs for groups from the same multicast source address). If per-group map in receiver MVPN maps multicast streams sourced from the same multicast source address to multiple core routing instance MVPNs, then the first PIM join processed for those streams selects the core routing instance MVPN to be used for all multicast streams from a given source address for this receiver MVPN. PIM joins for streams sourced from the source address not carried by the selected core VRF MVPN instance will remain unresolved. When a PIM join/prune is received in a receiver routing instance MVPN with per-group mapping configured, if no mapping is defined for the PIM join’s group address, non-extranet processing applies when resolving how to forward the PIM join/prune.
The main attributes for per-group SSM extranet mapping on receiver PE include support for:
- Rosen MVPN with MDT SAFI. * RFC6513/6514 NG-MVPN with IPv4 RSVP-TE/mLDP in P-instance (a P-instance tunnel must be in the same VPRN service as multicast source)
- IPv4 PIM SSM
- IGMP (C-S, C-G), and for IGMP (C-*, C-G) using SSM translation
- a receiver routing instance MVPN to map groups to multiple core routing instance MVPNs
- in-service changes of the map to a different transit/source core routing instance (this is service affecting)
Caveats:
- When a receiver routing instance MVPN is on the same PE as a source routing instance MVPN, basic extranet functionality and not per-group (C-S, C-G) mapping must be configured (extranet from receiver routing instance to core routing instance to source routing instance on a single PE is not supported).
- Local receivers in the core routing instance MVPN are not supported when per-group mapping is deployed.
- Receiver routing instance MVPN that has per-group mapping enabled cannot have tunnels in its OIF lists.
- Per-group mapping is blocked if GRT/VRF extranet is configured.
3.4.8.4. Multicast GRT-source/VRF-receiver Extranet with Per Group Mapping for PIM SSM
Multicast GRT-source/VRF-receiver (GRT/VRF) extranet with per-group mapping allows multicast traffic to flow from GRT into VRF MVPN instances. A VRF routing instance that received a PIM/IGMP join but cannot reach the source multicast stream directly within its own instance is selected as receiver routing instance. A GRT instance that has sources of multicast streams and accepts PIM joins from other VRF MVPN instances is selected as source routing instance.
Figure 32 depicts a sample deployment.
Figure 32: GRT/VRF Extranet
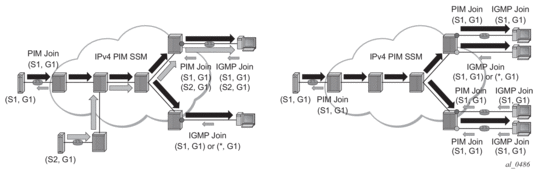
Routing information is exchanged between GRT and VRF receiver MVPN instances of extranet by enabling grt-extranet under a receiver MVPN PIM configuration for all or a subset of multicast groups. When enabled, multicast receivers in a receiver routing instance(s) can subscribe to streams from any multicast source node reachable in GRT source instance.
The main feature attributes are:
- GRT/VRF extranet can be performed on all streams or on a configured group of prefixes within a receiver routing instance.
- GRT instance requires Classic Rosen multicast.
- IPv4 PIM joins are supported in receiver VRF instances.
- Local receivers using IGMP: (C-S, C-G) and (C-*, C-G) using SSM translation are supported.
- The feature is blocked if a per-group mapping extranet is configured in receiver VRF.
3.4.8.5. Multicast Extranet with Per-group Mapping for PIM ASM
Multicast extranet with per-group mapping for PIM ASM allows multicast traffic to flow from a source routing instance to a receiver routing instance when a PIM ASM join is received in the receiver routing instance.
Figure 33 depicts PIM ASM extranet map support.
Figure 33: Multicast Extranet with per group PIM ASM mapping
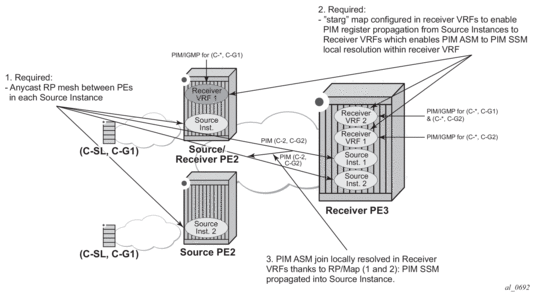
PIM ASM extranet is achieved by local mapping from the receiver to source routing instances on a receiver PE. The mapping allows propagation of anycast RP PIM register messages between the source and receiver routing instances over an auto-created internal extranet interface. This PIM register propagation allows the receiver routing instance to resolve PIM ASM joins to multicast source(s) and to propagate PIM SSM joins over an auto-created extranet interface to the source routing instance. PIM SSM joins are then propagated towards the multicast source within the source routing instance.
The following MVPN topologies are supported:
- Rosen MVPN with MDT SAFI: a local replication on a source PE and multiple-source/multiple-receiver replication on a receiver PE
- RFC 6513/6514 NG-MVPN (including RFC 6625 (C-*, C-*) wildcard S-PMSI): a local replication on a source PE and a multiple source/multiple receiver replication on a receiver PE
- Extranet for GRT-source/VRF receiver with a local replication on a source PE and a multiple-receiver replication on a receiver PE
- Locally attached receivers are supported without SSM mapping.
To achieve the extranet replication, the operator must configure:
- local PIM ASM mapping on a receiver PE from a receiver routing instance to a source routing instance (config>service>vprn>mvpn>rpf-select>core-mvpn or config>service>vprn>pim>grt-extranet as applicable)
- an anycast RP mesh between source and receiver PEs in the source routing instance
Caveats:
- This feature is supported for IPv4 multicast.
- The multicast source must reside in the source routing instance the ASM map points to on a receiver PE (the deployment of transit replication extranet from source instance to core instance on Source PE with ASM map extranet from receiver instance to core instance on a receiver PE is not supported).
- A given multicast group can be mapped in a receiver routing instance using either PIM SSM mapping or PIM ASM mapping but not both.
- A given multicast group cannot map to multiple source routing instances.
3.4.9. Non-Congruent Unicast and Multicast Topologies for Multicast VPN
Operators that prefer to keep unicast and multicast traffic on separate links in a network have the option to maintain two separate instances of the route table (unicast and multicast) per VPRN.
Multicast BGP can be used to advertise separate multicast routes using Multicast NLRI (SAFI 2) on PE-CE link within VPRN instance. Multicast routes maintained per VPRN instance can be propagated between PE-PE using BGP Multicast-VPN NLRI (SAFI 129).
Figure 34: Incongruent Multicast and Unicast Topology for Non-Overlapping Traffic Links
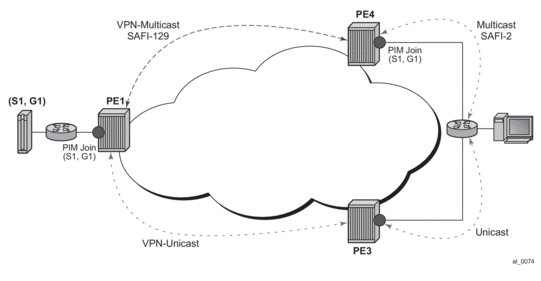
SR OS supports option to perform RPF check per VPRN instance using multicast route table, unicast route table or both.
Non-congruent unicast and multicast topology is supported with NG-MVPN. Draft Rosen is not supported.
3.4.10. Automatic Discovery of Group-to-RP Mappings (Auto-RP)
Auto-RP is a proprietary group discovery and mapping mechanism for IPv4 PIM that is described in cisco-ipmulticast/pim-autorp-spec, Auto-RP: Automatic discovery of Group-to-RP mappings for IP multicast. The functionality is similar to the IETF standard bootstrap router (BSR) mechanism that is described in RFC 5059, Bootstrap Router (BSR) Mechanism for Protocol Independent Multicast (PIM), to dynamically learn about the availability of Rendezvous Points (RPs) in a network. When a router is configured as an RP-mapping agent with the pim>rp>auto-rp-discovery command, it listens to the CISCO-RP-ANNOUNCE (224.0.1.39) group and caches the announced mappings. The RP-mapping agent then periodically sends out RP-mapping packets to the CISCO-RP-DISCOVERY (224.0.1.40) group. SR OS supports version 1 of the auto-RP specification, so the ability to deny RP-mappings by advertising negative group prefixes is not supported.
PIM dense-mode (PIM-DM) as described in RFC 3973, Protocol Independent Multicast - Dense Mode (PIM-DM): Protocol Specification (Revised), is used for the auto-RP groups to support multihoming and redundancy. The RP-mapping agent supports announcing, mapping, and discovery functions; candidate RP functionality is not supported.
Auto-RP is supported for IPv4 in multicast VPNs and in the global routing instance. Either BSR or auto-RP for IPv4 can be configured; the two mechanisms cannot be enabled together. BSR for IPv6 and auto-RP for IPv4 can be enabled together. In a multicast VPN, auto-RP cannot be enabled together with sender-only or receiver-only multicast distribution trees (MDTs), or wildcard S-PMSI configurations that could block flooding.
3.4.11. IPv6 MVPN Support
IPv6 multicast support in SR OS allows operators to offer customers IPv6 multicast MVPN service. An operator utilizes IPv4 mLDP or RSVP-TE core to carry IPv6 c-multicast traffic inside IPv4 mLDP or RSVP-TE provider tunnels (p-tunnels). The IPv6 customer multicast on a given MVPN can be blocked, enabled on its own or in addition to IPv4 multicast per PE or per interface. When both IPv4 and IPv6 multicast is enabled for a given MVPN, a single tree is used to carry both IPv6 and IPv4 traffic. Figure 35 shows an example of an operator with IPv4 MPLS backbone providing IPv6 MVPN service to Customer 1 and Customer 2.
Figure 35: IPv6 MVPN Example
SR OS IPv6 MVPN multicast implementation provides the following functionality:
- IPv6 C-PIM-SM (ASM and SSM)
- MLDv1 and MLDv2
- SSM mapping for MLDv1
- I-PMSI and S-PMSI using IPv4 P2MP mLDP p-tunnels
- I-PMSI and S-PMSI using IPv4 P2MP RSVP p-tunnels
- BGP auto-discovery
- PE-PE transmission of C-multicast routing using BGP mvpn-ipv6 address family
- IPv6 BSR/RP functions on functional par with IPv4 (auto-RP using IPv4 only)
- Embedded RP
- Inter-AS Option A
The following known caveats exist for IPv6 MVPN support:
- Non-congruent topologies are not supported
- IPv6 is not supported in MCAC
- If IPv4 and IPv6 multicast is enabled, per-MVPN multicast limits apply to entire IPv4 and IPv6 multicast traffic as it is carried in a single PMSI. For example IPv4 AND IPv6 S-PMSIs are counted against a single S-PMSI maximum per MVPN.
- IPv6 Auto-RP is not supported
3.4.12. Multicast Core Diversity for Rosen MDT_SAFI MVPNs
Figure 36 depicts Rosen MVPN core diversity deployment:
Figure 36: Multicast Core Diversity
Core diversity allows operator to optionally deploy multicast MVPN in either default IGP instance or one of two non-default IGP instances to provide, for example, topology isolation or different level of services. The following describes main feature attributes:
- Rosen MVPN IPv4 multicast with MDT SAFI is supported with default and data MDTs.
- Rosen MVPN can use a non-default OSPF or ISIS instance (using their loopback addresses instead of a system address).
- Up to 3 distinct core instances are supported: system + 2 non-default OSPF instances – referred as “red” and “blue” below.
- The BGP Connector also uses non-default OSPF loopback as NH, allowing Inter-AS Option B/C functionality to work with Core diversity as well.
- The feature is supported with CSC-VPRN.
On source PEs (PE1: UMH, PE2: UMH in Figure 36), an MVPN is assigned to a non-default IGP core instance as follows:
- MVPN is statically pointed to use one of the non-default “red”/“blue” IGP instances loopback addresses as source address instead of system loopback IP.
- MVPN export policy is used to change unicast route next-hop VPN address (no longer required as of SR OS Release 12.0.R4 - BGP Connector support for non-default instances).
The above configuration ensures that MDT SAFI and IP-VPN routes for the non-default core instance use non-default IGP loopback instead of system IP. This ensures PIM advertisement/joins run in the proper core instance and GRE tunnels for multicast can be set-up using and terminated on non-system IP.
If BGP export policy is used to change unicast route next-hop VPN address, unicast traffic must be forwarded in non-default “red” or “blue” core instance LDP or RSVP (terminating on non-system IP) must be used. GRE unicast traffic termination on non-system IP is not supported, and any GRE traffic arriving at the PE in “blue”, “red” instances destined to non-default IGP loopback IP will be forwarded to CPM (ACL or CPM filters can be used to prevent the traffic from reaching the CPM). This limitation does not apply if BGP connector attribute is used to resolve the multicast route.
No configuration is required on non-source PEs.
Feature caveats:
- VPRN instance must be shutdown to change the mdt-safi source-address. The CLI rollback that includes change of the auto-discovery is thus service impacting.
- To reset mdt-safi source-address to system IP, operator must first execute no auto-discovery (or auto-discovery default) then auto-discovery mdt-safi
- Configuring system IP as a source-address will consume one of the 2 IP addresses allowed, thus it should not be done.
- Operators must configure proper IGP instance loopback IP addresses within Rosen MVPN context and must configure proper BGP policies (prior to release 12.0.R4) for the feature to operate as expected. There is no verification that the address entered for MVPN provider tunnel source-address is such an address or is not a system IP address.
3.4.13. NG-MVPN Core Diversity
See Figure 37 for an operational example of logical networks using Multi-Instance IGP.
Figure 37: Logical Networks Using Multi-Instance IGP
SR OS is being positioned in multi-instance IGP as a virtualization or migration strategy in numerous cases. One specific application is as a virtual LSR core whereby various topologies are created using separate IGP instances. Specifically, the migration to SR solutions requires the deployment of multi-instance IGP with service migrations. The objective is to more cleanly segregate protocols and service bindings to specific routing instances. NG-MVPN does not currently allow non-system loopbacks to be used for PMSI (for example, MVPN address family).
The ability to support binding MVPN with mLDP tunnels to different loopback interfaces is one of the main requirements. In addition, assigning these loopback interfaces to different IGP instances will create parallel NG-MVPN services, each running over a separate IGP instance.
This feature has two main components to it:
- The ability of advertising a MVPN route, via a loopback interface, and generating an mLDP FEC with that loopback interface.
- The ability of creating multiple IGP instances and assigning a loopback to each IGP instance. This, combined with the component above, will create parallel NG-MVPN services on different IGP instances.
3.4.13.1. NG-MVPN to Loopback Interface
Figure 38: NG-MVPN Setup Via Loopback Interface
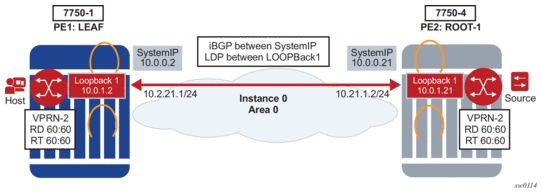
SystemIP is usually used for management purposes and, as such, it might be desired to create services to a separate loopback interface. Due to security concerns, many operators do not want to create services to the systemIP address.
The first portion of this feature will allow MVPN routes be advertised with a nexthop specific loopback.
This can be achieved via two methods:
- Having iBGP session to the loopback interface of the peer, and using the corresponding local loopback for local-address.
- Having iBGP session to the systemIP but using policies to change the nexthop of the AD route to the corresponding loopback interface.
After the AD routes are advertised via the loopback interface as nexthop, PIM will generate an mLDP FEC for the loopback interface.
The preceding configuration will allow an NG-MVPN to be established via a specific loopback.
Figure 39: Intra-as Basic Opaque FEC to Loopback Interface
It should be noted that this setup will work in a single area or multi-area through an ABR.
3.4.13.2. NG-MVPN Core Diversity
Figure 40: Core Diversity with Parallel NG-MVPN Services on Parallel IGP Instances
In Figure 40, Red and Blue networks correspond to separate IGP instances tied to separate loopback interfaces. In core diversity, MVPN services on the LER are bound to a domain by advertising MP-BGP routes, with next hop set to the appropriate loopback address, and having the receiving LERs resolve those BGP next hops, based on the corresponding IGP instance. All subsequent MVPN BGP routing exchanges must set and resolve the BGP next hop with the configured non-system loopback.
With this feature, an MP-BGP next hop would resolve to a link LDP label which is indirectly associated with a given IGP instance. Services which advertise BGP routes with next hop red loopback would result in traffic flowing over the Red network using LDP and blue loopback would result in traffic flowing over Blue network. See Figure 40.
Most importantly, the common routes in each IGP instance must have a unique and active label. This is required to ensure that the same route advertised in two different IGP domains do not resolve to the same label. LDP local-lsr-id can be used to ensure FECs and label mapping be advertised via the right instance of IGP.
Core diversity allows an operator to optionally deploy multicast NG-MVPN in either default IGP instance or one of the non-default IGP instances to provide, for example, topology isolation or different level of services. The following describes the main feature attributes:
- NG- MVPN can use IPv4/IPv6 multicast.
- NG-MVPN can use a non-default OSPF or ISIS instance.
- The BGP Connector also uses non-default OSPF loopback as NH, via two methods:
- Setting the BGP local-address to a loopback interface IP address
- Creating a routing policy to set the NH of a MVPN AD route to the corresponding loopback IP
- RSVP-TE/LDP transport tunnels also use non-systemIP loopback for session creation. As an example, RSVP-TE p2mp LSPs would be created to non systemIP loopbacks and mLDP will create a session via local-lsr-id.
- Need to add the source-address for mvpn auto-discover default.
| Note: This is accomplished by using their loopback addresses instead of a system address. |
On the source PEs, a NG-MVPN is assigned to a non-default IGP core instance as follows:
- NG-MVPN is statically pointed to use one of the non-default red/blue IGP instances loopback addresses as source address instead of system loopback IP.
- MVPN export policy is used to change unicast route next-hop VPN address (BGP Connector support for non-default instances).
- Alternatively, the BGP local-address can be set to the correct loopback interface assigned for that specific instance.
The preceding configuration ensures that MVPN-IPv4/v6 and IP-VPN routes for the non-default core instance use non-default IGP loopback instead of system IP. This ensures MVPN-IPv4/v6 advertisement/joins run in the proper core instance and mLDP and P2MP RSVP tunnels (I-PMSI and S-PMSI) for multicast can be set-up using and terminating on non-system IP.
If BGP export policy is used to change unicast route next-hop VPN address, than unicast traffic must be forwarded in non-default red or blue core instance LDP or RSVP (terminating on non-system IP) must be used.
3.4.13.3. Configuration Example
Figure 41: Core Diversity with Parallel NG-MVPN Services on Parallel IGP Instances
In Figure 41, there are three IGP instances, the default Instance 0, Instance 1, and Instance 2. Each instance will bind to its own loopback interface. For Instance 0, it will be the systemIP system Interface used as loopback. LDP, RSVP and MP-BGP need to run between the corresponding loopback associated with each instance.
For example, for the blue Instance 2, both MP-BGP and LDP need to be configured to its corresponding loopback loopback2 and the next-hop for BGP MVPN-IP4/IPv6 and the VPN-IPv4/IPv6 need to be loopback2.
From a configuration point of view, the following steps need to be taken:
- For MLDP, configure LDP with local-lsr-id with loopback interface of instance 2 loopback2:*A:SwSim14>config>router>ldp# infointerface-parametersinterface “2ROOT” dual-stackipv4local-lsr-id interface-name “loopback2”no shutdownexitno shutdownexit
- Enable the source-address for default auto discover as follows:*A:Dut-A>config>service>vprn 2mvpn auto-discovery default source-address LOOPBack1vrf-export “vprnexp100”*A:Dut-A>config>service>vprn 3mvpn auto-discovery default source-address LOOPBack2vrf-export “vprnexp101”
- Define community vprnXXXX for each VPRN using non-default core-instance and define a policy to tag each VPRN with either a blue or red standard community attribute:*A:Dut-A>config>router>policy-options# infocommunity "vprn2" members "target:70:70"community "vprn3" members "target:80:80"policy-statement "vprnexp2"entry 10fromprotocol directexitaction acceptcommunity add "vprn2" "red"exitexitpolicy-statement "vprnexp3"entry 10fromprotocol directexitaction acceptcommunity add "vprn3" "blue"exitexitexit
- Define a single global BGP policy to change next hop for red/blue MVPNs:*A:Dut-A>config>router>policy-options# infopolicy-statement "MVPN_CoreDiversity_Exp"entry 10fromcommunity "red"exittoprotocol bgp-vpnexitaction acceptnext-hop loopback1exitexitentry 20fromcommunity "blue"exittoprotocol bgp-vpnexitaction acceptnext-hop loopback2exitexitexit
- Configure BGP default MVPN export in the group as required:configure router bgp group "mvpn" export "MVPN_CoreDiveristy_Exp"
- Configure each VPRN to use proper IGP source address and proper VRF export policy:*A:Dut-A>config>service>vprn 2mvpn auto-discovery default source-address loopback1vrf-export "vprnexp2"*A:Dut-A>config>service>vprn 3mvpn auto-discovery default source-address loopback2vrf-export "vprnexp3"
3.4.14. NG-MVPN Multicast Source Geo-Redundancy
Multicast source geo-redundancy is targeted primarily for MVPN deployments for multicast delivery services like IPTV. The solutions allows operators to configure a list of geographically dispersed redundant multicast sources (with different source IPs) and then, using configured BGP policies, ensure that each Receiver PE (a PE with receivers in its C-instance) selects only a single, most-preferred multicast source for a given group from the list. Although the data may still be replicated in P-instance (each multicast source sends (C-S, C-G) traffic onto its I-PMSI tree or S-PMSI tree), each Receiver PE only forwards data to its receivers from the preferred multicast source. This allows operators to support multicast source geo-redundancy without the replication of traffic for each (C-S, C-G) in the C-instance while allowing fast recovery of service when an active multicast source fails.
Figure 42 shows an operational example of multicast source geo-redundancy:
Figure 42: Preferred Source Selection for Multicast Source Geo-Redundancy
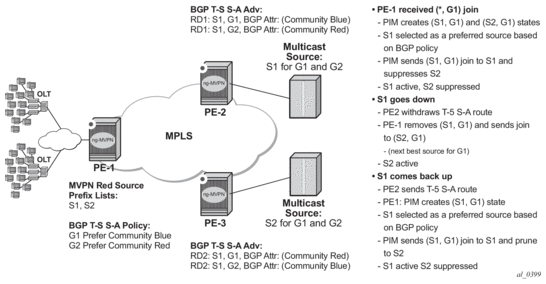
Operators can configure a list of prefixes for multicast source redundancy per MVPN on Receiver PEs:
- Up to 8 multicast source prefixes per VPRN are supported.
- Any multicast source that is not part of the source prefix list is treated as a unique source and automatically joined in addition to joining the most preferred source from the redundant multicast source list.
A Receiver PE selects a single, most-preferred multicast source from the list of pre-configured sources for a given MVPN during (C-*, C-G) processing as follows:
- A single join for the group is sent to the most preferred multicast source from the operator-configured multicast source list. Joins to other multicast sources for a given group are suppressed. Operator can see active and suppressed joins on a Receiver PE. Although a join is sent to a single multicast source only, (C-S, C-G) state is created for every source advertising Type-5 S-A route on the Receiver PE.
- The most preferred multicast source is a reachable source with the highest local preference for Type-5 SA route based on the BGP policy, as described later in this section.
- On a failure of the preferred multicast source or when a new multicast source with a better local preference is discovered, Receiver PE will join the new most-preferred multicast source. The outage experienced will depend on how quickly Receiver PE receives Type-5 S-A route withdrawal or loses unicast route to multicast source, and how quickly the network can process joins to the newly selected preferred multicast source(s).
- Local multicast sources on a Receiver PE are not subject to the most-preferred source selection, regardless of whether they are part of redundant source list or not.
BGP policy on Type-5 SA advertisements is used to determine the most preferred multicast source based on the best local preference as following:
- Each Source PE (a PE with multicast sources in its C-instance) tags Type-5 SA routes with a unique standard community attribute using global BGP policy or MVPN vrf-export policy. Depending on multicast topology, the policy may require source-aware tagging in the policy. Either all MVPN routes or Type 5 SA routes only can be tagged in the policy (new attribute mvpn-type 5).
- Each receiver PE has a BGP VRF import policy that sets local preference using match on Type-5 SA routes (new attribute mvpn-type 5) and standard community attribute value (as tagged by the Source PEs). Using policy statements that also include group address match, allows receiver PEs to select the best multicast source per group. The BGP VRF import policy must be applied as vrf-import under config>service>vprn>mvpn context. It must have default-action accept specified, or all MVPN routes other than those matched by specified entries will be rejected. In addition, it must have vrf-target as a community match condition, because vrf-target mvpn configuration is ignored when vrf-import policy is defined.
Operators can change redundant source list or BGP policy affecting source selection in service. If such a change of the list/policy results in a new preferred multicast source election, make-before-break is used to join the new source and prune the previously best source.
For the proper operations, MVPN multicast source geo-redundancy requires the router:
- To maintain the list of eligible multicast sources on Receiver PEs, Source PE routers must generate Type-5 S-A route even if the Source PE sees no active joins from any receiver for a given group.
- To trigger a switch from a currently active multicast source on a Receiver PE, Source PE routers must withdraw Type-5 S-A route when the multicast source fails or alternatively unicast route to multicast source must be withdrawn or go down on a Receiver PE.
MVPN multicast source redundancy solutions is supported for the following configurations only. Enabling the feature in unsupported configuration must be avoided:
- NG-MVPN with RSVP-TE or mLDP or PIM with BGP c-multicast signaling in P-instance. Both I-PMSI and S-PMSI trees are supported.
- IPv4 and IPv6 (C-*, C-G) PIM ASM joins in the C-instance.
- Both intersite-shared enabled and disabled are supported. For intersite-shared enabled, operators must enable generation of Type-5 S-A routes even in the absence of receivers seen on Source PEs (intersite-shared persistent-type5-adv must be enabled).
- The Source PEs must be configured as a sender-receiver, the Receiver PEs can be configured as a sender-receiver or a receiver-only.
- The RP(s) must be on the Source PE(s) side. Static RP, anycast-RP, embedded-RP types are supported.
- UMH redundancy can be deployed to protect Source PE to any multicast source. When deployed, UMH selection is executed independently of source selection after the most preferred multicast source had been chosen. Supported umh-selection options include: highest-ip, hash-based, tunnel-status (not supported for IPv6), and unicast-rt-pref.
3.4.15. Multicast Core Diversity for Rosen MDT SAFI MVPNs
Figure 43 shows a Rosen MVPN core diversity deployment.
Figure 43: Multicast Core Diversity
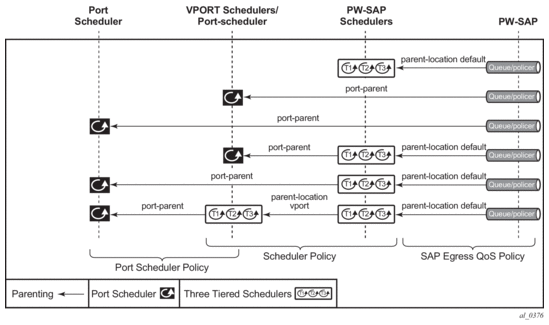
Core diversity allows operators to optionally deploy multicast MVPN in either default IGP instance. or one of two non-default IGP instances to provide; for example, topology isolation or different level of services. The following describes the main feature attributes:
- Rosen MVPN IPv4 multicast with MDT SAFI is supported with default and data MDTs.
- Rosen MVPN can use a non-default OSPF or ISIS instance (using their loopback addresses instead of a system address).
- Up to 3 distinct core instances are supported: system + 2 non-default OSPF instances shown in Figure 43.
- The BGP Connector also uses non-default OSPF loopback as NH, allowing Inter-AS Option B/C functionality to work with Core diversity as well.
- The feature is supported with CSC-VPRN.
On source PEs (PE1: UMH, PE2: UMH in the above picture), an MVPN is assigned to a non-default IGP core instance as follows:
- MVPN is statically pointed to use one of the non-default IGP instances loopback addresses as source address instead of system loopback IP.
- MVPN export policy is used to change unicast route next-hop VPN address.
- BGP Connector support for non-default instances.
The configuration shown above ensures that MDT SAFI and IP-VPN routes for the non-default core instance use non-default IGP loopback instead of system IP. This ensures PIM advertisement/joins run in the proper core instance and GRE tunnels for multicast can be set-up using and terminated on non-system IP. If BGP export policy is used to change unicast route next-hop VPN address instead of BGP Connector attribute-based processing and unicast traffic must be forwarded in non-default core instances 1 or 2, LDP or RSVP (terminating on non-system IP) must be used. GRE unicast traffic termination on non-system IP is not supported and any GRE traffic arriving at the PE in instances 1 or 2, destined to non-default IGP loopback IP will be forwarded to CPM (ACL or CPM filters can be used to prevent the traffic from reaching the CPM).
No configuration is required on non-source PEs.
Known feature caveats include:
- VPRN instance must be shutdown to change the mdt-safi source-address. The CLI rollback that includes change of the auto-discovery is thus service impacting.
- To reset mdt-safi source-address to system IP, operator must first execute no auto-discovery (or auto-discovery default) then auto-discovery mdt-safi
- Configuring system IP as a source-address will consume one of the 2 IP addresses allowed, thus it should not be done.
- Operators must configure proper IGP instance loopback IP addresses within Rosen MVPN context and must configure proper BGP policies (prior to release 12.0R4) for the feature to operate as expected. There is no verification that the address entered for MVPN provider tunnel source-address is such an address or is not a system IP address.
3.4.16. Inter-AS MVPN
The Inter-AS MVPN feature allows set-up of Multicast Distribution Trees (MDTs) that span multiple Autonomous Systems (ASes).This section focuses on multicast aspects of the Inter-AS MVPN solution.
To support Inter-AS option for MVPNs, a mechanism is required that allows setup of Inter-AS multicast tree across multiple ASes. Due to limited routing information across AS domains, it is not possible to setup the tree directly to the source PE. Inter-AS VPN Option A does not require anything specific to inter-AS support as customer instances terminate on ASBR and each customer instance is handed over to the other AS domain via a unique instance. This approach allows operators to provide full isolation of ASes, but the solution is the least scalable case, as customer instances across the network have to exist on ASBR.
Inter-AS MVPN Option B allows operators to improve upon the Option A scalability while still maintaining AS isolation, while Inter-AS MVPN Option C further improves Inter-AS scale solution but requires exchange of Inter-AS routing information and thus is typically deployed when a common management exists across all ASes involved in the Inter-AS MVPN. The following sub-sections provide further details on Inter-AS Option B and Option C functionality.
3.4.16.1. BGP Connector Attribute
BGP connector attribute is a transitive attribute (unchanged by intermediate BGP speaker node) that is carried with VPNv4 advertisements. It specifies the address of source PE node that originated the VPNv4 advertisement.
With Inter-AS MVPN Option B, BGP next-hop is modified by local and remote ASBR during re-advertisement of VPNv4 routes. On BGP next-hop change, information regarding the originator of prefix is lost as the advertisement reaches the receiver PE node.
BGP connector attribute allows source PE address information to be available to receiver PE, so that a receiver PE is able to associate VPNv4 advertisement to the corresponding source PE.
3.4.16.2. PIM RPF Vector
In case of Inter-AS MVPN Option B, routing information towards the source PE is not available in a remote AS domain, since IGP routes are not exchanged between ASes. Routers in an AS other than that of a source PE, have no routes available to reach the source PE and thus PIM JOINs would never be sent upstream. To enable setup of MDT towards a source PE, BGP next-hop (ASBR) information from that PE's MDT-SAFI advertisement is used to fake a route to the PE. If the BGP next-hop is a PIM neighbor, the PIM JOINs would be sent upstream. Otherwise, the PIM JOINs would be sent to the immediate IGP next-hop (P) to reach the BGP next-hop. Since the IGP next-hop does not have a route to source PE, the PIM JOIN would not be propagated forward unless it carried extra information contained in RPF Vector.
In case of Inter-AS MVPN Option C, unicast routing information towards the source PE is available in a remote AS PEs/ASBRs as BGP 3107 tunnels, but unavailable at remote P routers. If the tunneled next-hop (ASBR) is a PIM neighbor, the PIM JOINs would be sent upstream. Otherwise, the PIM JOINs would be sent to the immediate IGP next-hop (P) to reach the tunneled next-hop. Since the IGP next-hop does not have a route to source PE, the PIM JOIN would not be propagated forward unless it carried extra information contained in RPF Vector.
To enable setup of MDT towards a source PE, PIM JOIN thus carries BGP next hop information in addition to source PE IP address and RD for this MVPN. For option-B, both these pieces of information are derived from MDT-SAFI advertisement from the source PE. For option-C, both these pieces of information are obtained from the BGP tunneled route.
The RPF vector is added to a PIM join at a PE router when configure router pim rpfv option is enabled. P routers and ASBR routers must also have the option enabled to allow RPF Vector processing. If the option is not enabled, the RPF Vector is dropped and the PIM JOIN is processed as if the PIM Vector were not present.
For further details about RPF Vector processing please refer to [RFCs 5496, 5384 and 6513]
3.4.16.3. Inter-AS MVPN Option B
Inter-AS Option B is supported for Rosen MVPN PIM SSM using BGP MDT SAFI, PIM RPF Vector and BGP Connector attribute. The Figure 44 depict set-up of a default MDT:
Figure 44: Inter-AS Option B Default MDT Setup
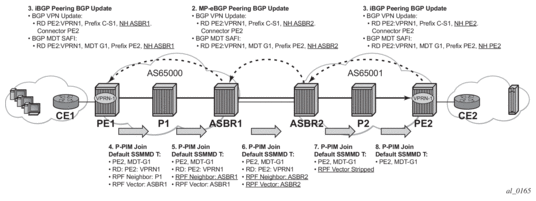
SR OS inter-AS Option B is designed to be standard compliant based on the following RFCs:
- RFC 5384 - The Protocol Independent Multicast (PIM) Join Attribute Format
- RFC 5496 - The Reverse Path Forwarding (RPF) Vector TLV
- RFC 6513 - Multicast in MPLS/BGP IP VPNs
The SR OS implementation was designed also to interoperate with older routers Inter-AS implementations that do not comply with the RFC 5384 and RFC 5496.
3.4.16.4. Inter-AS MVPN Option C
Inter-AS Option C is supported for Rosen MVPN PIM SSM using BGP MDT SAFI and PIM RPF Vector. Figure 45 depicts a default MDT setup:
Figure 45: Inter-AS Option C Default MDT Setup
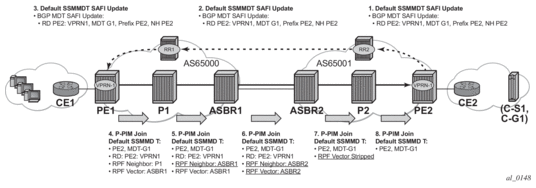
Additional caveats for Inter-AS MVPN Option B and C support are the following:
- Inter-AS MVPN Option B is not supported with duplicate PE addresses.
- For Inter-AS Option C, BGP 3107 routes are installed into unicast rtm (rtable-u), unless routes are installed by some other means into multicast rtm (rtable-m), and Option C will not build core MDTs, therefore, rpf-table is configured to rtable-u or both.
- Additional Cisco interoperability notes are the following:
- RFC 5384 - the Protocol Independent Multicast (PIM) Join Attribute Format
- RFC 5496 - the Reverse Path Forwarding (RPF) Vector TLV
- RFC 6513 - multicast in MPLS/BGP IP VPNs
The SR OS implementation was designed to inter-operate with Cisco routers Inter-AS implementations that do not comply with the RFC5384 and RFC5496.
When configure router pim rpfv mvpn option is enabled, Cisco routers need to be configured to include RD in an RPF vector using the following command: ip multicast vrf vrf-name rpf proxy rd vector for interoperability. When Cisco routers are not configured to include RD in an RPF vector, operator should configure SR OS router (if supported) using configure router pim rpfv core mvpn: PIM joins received can be a mix of core and mvpn RPF vectors.
3.4.16.5. NG-MVPN Non-segmented Inter-AS Solution
This feature allows multicast services to use segmented protocols and span them over multiple autonomous systems (ASs), as done in unicast services. As IP VPN or GRT services span multiple IGP areas or multiple ASs, either due to a network designed to deal with scale or as result of commercial acquisitions, operators may require Inter-AS VPN (unicast) connectivity. For example, an Inter-AS VPN can break the IGP, MPLS and BGP protocols into access segments and core segments, allowing higher scaling of protocols by segmenting them into their own islands. SR OS also allows for similar provision of multicast services and for spanning these services over multiple IGP areas or multiple ASs.
For multicast VPN (MVPN), SR OS previously supported Inter-AS Model A/B/C for Rosen MVPN; however, when MPLS was used, only Model A was supported for Next Generation Multicast VPN (NG-MVPN) and d-mLDP signaling.
For unicast VPRNs, the Inter-AS or Intra-AS Option B and C breaks the IGP, BGP and MPLS protocols at ABR routers (in case of multiple IGP areas) and ASBR routers (in case of multiple ASs). At ABR and ASBR routers, a stitching mechanism of MPLS transport is required to allow transition from one segment to next, as shown in Figure 46 and Figure 47.
In Figure 46, the Service Label (S) is stitched at the ASBR routers.
Figure 46: Unicast VPN Option B with Segmented MPLS
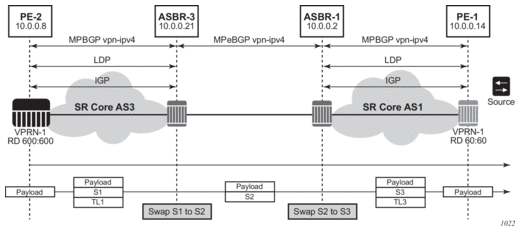
In Figure 47, the 3107 BGP Label Route (LR) is stitched at ASBR1 and ASBR3. At ASBR1, the LR1 is stitched with LR2, and at ASBR3, the LR2 is stitched with TL2.
Figure 47: Unicast VPN Option C with Segmented MPLS
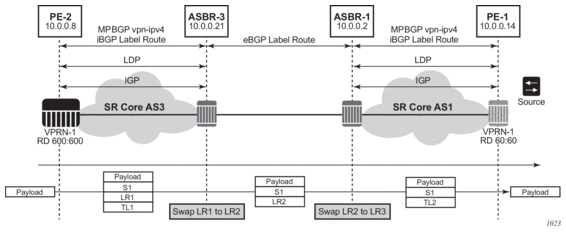
Previously, in case of NG-MVPN, segmenting an LDP MPLS tunnel at ASBRs or ABRs was not possible. As such, RFC 6512 and 6513 used a non-segmented mechanism to transport the multicast data over P-tunnels end-to-end through ABR and ASBR routers. The signaling of LDP needed to be present and possible between two ABR routers or two ASBR routers in different ASs.
| Note: For unicast VPNs, it was usually preferred to only have eBGP between ASBR routers. The non-segmented behavior of d-mLDP would have broken this by requiring LDP signaling between ASBR routers. |
SR OS now has d-mLDP non-segmented intra-AS and inter-AS signaling for NG-MVPN and GRT multicast. The non-segmented solution for d-mLDP is possible for inter-ASs as Option B and C.
3.4.16.5.1. Non-Segmented d-mLDP and Inter-AS VPN
There are three types of VPN Inter-AS solutions:
Options B and C use recursive opaque types 8 and 7 respectively, from Table 37.
Table 37: Recursive Opaque Types
Opaque Type | Opaque Name | RFC | SR OS Use |
1 | Basic Type | RFC 6388 | VPRN Local AS |
3 | Transit IPv4 | RFC 6826 | IPv4 multicast over mLDP in GRT |
4 | Transit IPv6 | RFC 6826 | IPv6 multicast over mLDP in GRT |
7 | Recursive Opaque (Basic Type) | RFC 6512 | Inter-AS Option C MVPN over mLDP |
8 | Recursive Opaque (VPN Type) | RFC 6512 | Inter-AS Option B MVPN over mLDP |
3.4.16.5.1.1. Inter-AS Option A
In Inter-AS Option A, ASBRs communicate using VPN access interfaces, which need to be configured under PIM for the two ASBRs to exchange multicast information.
3.4.16.5.1.2. Inter-AS Option B
The recursive opaque type used for Inter-AS Option B is the Recursive Opaque (VPN Type), shown as opaque type 8 in Table 37.
Inter-AS Option B Support for NG-MVPN
Inter-AS Option B requires additional processing on ASBR routers and recursive FEC encoding than that of Inter-AS Option A. Because BGP adjacency is not e2e, ASBRs must cache and use a PMSI route to build the tree. For that, mLDP recursive FEC must carry RD information—thus, VPN recursive FEC is required (opaque type 8).
In Inter-AS Option B, the PEs in two different ASs do not have their system IP address in the RTM. As such, for NG-MVPN, a recursive opaque value in mLDP FEC is required to signal the LSP to the first ASBR in the local AS path.
Because the system IPs of the peer PEs (Root-1 and Root-2) are not installed on the local PE (leaf), it is possible to have two PEs in different ASs with same system IP address, as shown in Figure 48. However, SR OS does not support this topology. The system IP address of all nodes (root or leaf) in different ASs must be unique.
Figure 48: Identical System IP on Multiple PEs (Option B)
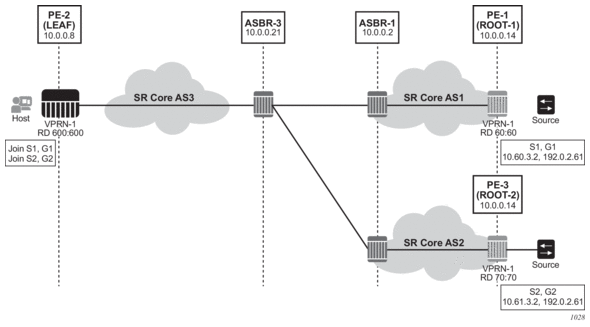
For inter-AS Option B and NG-MVPN, SR OS as a leaf does not support multiple roots in multiple ASs with the same system IP and different RDs; however, the first root that is advertised to an SR OS leaf will be used by PIM to generate an MLDP tunnel to this actual root. Any dynamic behavior after this point, such as removal of the root and its replacement by a second root in a different AS, is not supported and the SR OS behavior is nondeterministic.
I-PMSI and S-PMSI Establishment
I-PMSI and S-PMSI functionality follows RFC 6513 section 8.1.1 and RFC 6512 sections 3.1 and 3.2.1. For routing, the same rules as for GRT d-mLDP use case apply, but the VRR Route Import External community now encodes the VRF instance in the local administrator field.
Option B uses an outer opaque of type 8 and inter opaque of type 1 (see Table 37).
Figure 49 depicts the processing required for I-PMSI and S-PMSI Inter-AS establishment.
Figure 49: Non-segmented mLDP PMSI Establishment (Option B)
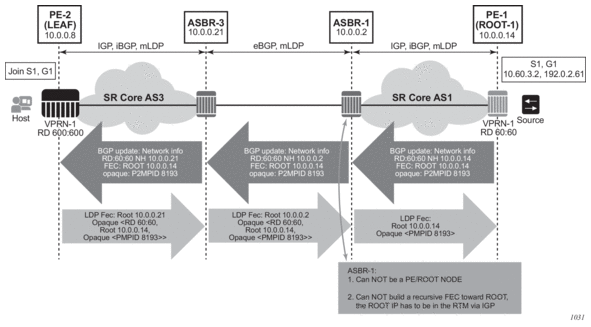
For non-segmented mLDP trees, A-D procedures follow those of the Intra-AS model, with the exception that NO EXPORT community must be excluded; LSP FEC includes mLDP VPN-recursive FEC.
For I-PMSI on Inter-AS Option B:
- A-D routes must be installed by ASBRs and next-hop information is changed as the routes are propagated, as shown in Figure 49.
- PMSI A-D routes are used to provide inter-domain connectivity on remote ASBRs.
On a receipt of an Intra-AS PMSI A-D route, PE2 resolves PE1’s address (next-hop in PMSI route) to a labeled BGP route with a next-hop of ASBR3, because PE1 (Root-1) is not known via IGP. Because ASBR3 is not the originator of the PMSI route, PE2 sources an mLDP VPN recursive FEC with a root node of ASBR3, and an opaque value containing the information advertised by Root-1 (PE-1) in the PMSI A-D route, shown below, and forwards the FEC to ASBR 3 using IGP.
PE-2 LEAF FEC: (Root ASBR3, Opaque value {Root: ROOT-1, RD 60:60, Opaque Value: P2MPLSP-ID xx}}
When the mLDP VPN-recursive FEC arrives at ASBR3, it notes that it is the identified root node, and that the opaque value is a VPN-recursive opaque value. Because Root-1 PE1 Is not known via IGP, ASBR3 resolves the root node of the VPN-Recursive FEC using PMSI A-D (I or S) matching the information in the VPN-recursive FEC (the originator being PE1 (Root-1), RD being 60:60, and P2MP LSP ID xx). This yields ASBR1 as next hop. ASBR3 creates a new mLDP FEC element with a root node of ASBR1, and an opaque value being the received recursive opaque value, as shown below. ASBR then forwards the FEC using IGP.
ASBR-3 FEC: {Root ASBR 1, Opaque Value {Root: ROOT-1, RD 60:60, Opaque Value: P2MPLSP-ID xx}}
When the mLDP FEC arrives at ASBR1, it notes that it is the root node and that the opaque value is a VPN-recursive opaque value. As PE1’s ROOT-1 address is known to ASBR1 through the IGP, no further recursion is required. Regular processing begins, using received Opaque mLDP FEC information.
ASBR-1 FEC: {Root: ROOT-1, Opaque Value: P2MP LSP-ID xx
| Note: VPN-Recursive FEC carries P2MPLSP ID. The P2MPLSP ID is used in addition to PE RD and Root to select a route to the mLDP root using the correct I-PMSI or S-PMSI route. |
The functionality as described above for I-PMSI applies also to S-PMSI and (C-*, C-*) S-PMSI.
C-multicast Route Processing
C-multicast route processing functionality follows RFC 6513 section 8.1.2 (BGP used for route exchange). The processing is analogous to BGP Unicast VPN route exchange described in Figure 46 and Figure 47. Figure 50 shows C-multicast route processing with non-segmented mLDP PMSI details.
Figure 50: Non-segmented mLDP C-multicast Exchange (Option B)
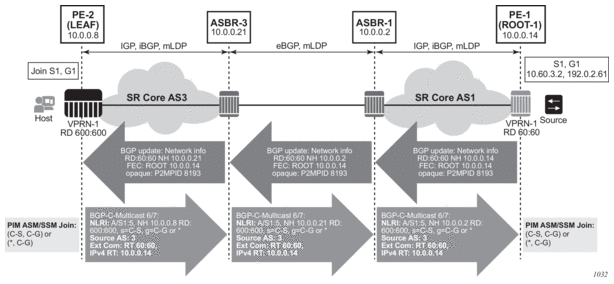
3.4.16.5.1.3. Inter-AS Option C
In Inter-AS Option C, the PEs in two different ASs have their system IP address in the RTM, but the intermediate nodes in the remote AS do not have the system IP of the PEs in their RTM. As such, for NG-MVPN, a recursive opaque value in mLDP FEC is need to signal the LSP to the first ASBR in the local AS path.
The recursive opaque type used for Inter-AS Option B is the Recursive Opaque (Basic Type), shown as opaque type 7 in Table 37.
3.4.16.5.1.3.1. Inter-AS Option C support for NG-MVPN
For Inter-AS Option C, on a leaf PE, a route exists to reach root PE’s system IP and, as ASBRs can use BGP unicast routes, recursive FEC processing using BGP unicast routes and not VPN recursive FEC processing using PMSI routes is required.
I-PMSI and S-PMSI Establishment
I-PMSI and S-PMSI functionality follows RFC 6513 section 8.1.1 and RFC 6512 Section 2. The same rules as per the GRT d-mLDP use case apply, but the VRR Route Import External community now encodes the VRF instance in the local administrator field.
Option C uses an outer opaque of type 7 and inter opaque of type 1.
Figure 51 shows the processing required for I-PMSI and S-PMSI Inter-AS establishment.
Figure 51: Non-segmented mLDP PMSI Establishment (Option C)
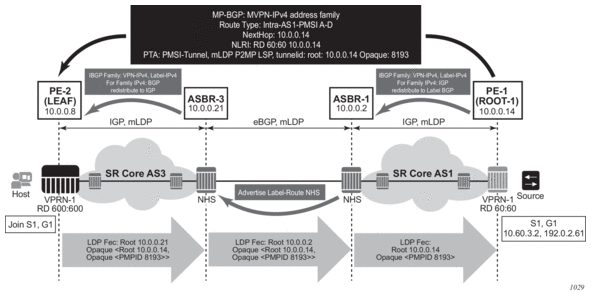
For non-segmented mLDP trees, A-D procedures follow those of the Intra-AS model, with the exception that NO EXPORT Community must be excluded; LSP FEC includes mLDP recursive FEC (and not VPN recursive FEC).
For I-PMSI on Inter-AS Option C:
- A-D routes are not installed by ASBRs and next-hop information is not changed in MVPN A-D routes.
- BGP-labeled routes are used to provide inter-domain connectivity on remote ASBRs.
On a receipt of an Intra-AS I-PMSI A-D route, PE2 resolves PE1’s address (N-H in PMSI route) to a labeled BGP route with a next-hop of ASBR3, because PE1 is not known via IGP. PE2 sources an mLDP FEC with a root node of ASBR3, and an opaque value, shown below, containing the information advertised by PE1 in the I-PMSI A-D route.
PE-2 LEAF FEC: {Root = ASBR3, Opaque Value: {Root: ROOT-1, Opaque Value: P2MP-ID xx}}
When the mLDP FEC arrives at ASBR3, it notes that it is the identified root node, and that the opaque value is a recursive opaque value. ASBR3 resolves the root node of the Recursive FEC (ROOT-1) to a labeled BGP route with the next-hop of ASBR1, because PE-1 is not known via IGP. ASBR3 creates a new mLDP FEC element with a root node of ASBR1, and an opaque value being the received recursive opaque value.
ASBR3 FEC: {Root: ASBR1, Opaque Value: {Root: ROOT-1, Opaque Value: P2MP-ID xx}}
When the mLDP FEC arrives at ASBR1, it notes that it is the root node and that the opaque value is a recursive opaque value. As PE-1’s address is known to ASBR1 through the IGP, no further recursion is required. Regular processing begins, using the received Opaque mLDP FEC information.
The functionality as described above for I-PMSI applies to S-PMSI and (C-*, C-*) S-PMSI.
C-multicast Route Processing
C-multicast route processing functionality follows RFC 6513 section 8.1.2 (BGP used for route exchange). The processing is analogous to BGP Unicast VPN route exchange. Figure 52 shows C-multicast route processing with non-segmented mLDP PMSI details.
Figure 52: Non-segmented mLDP C-multicast Exchange (Option C)
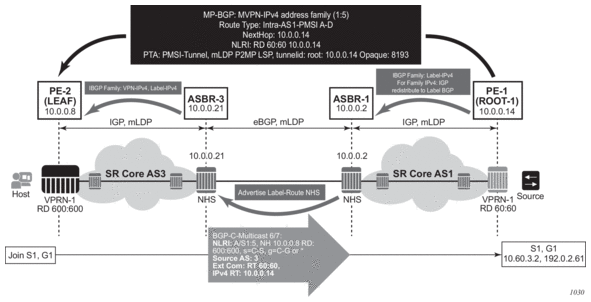
LEAF Node Cavities
| Caution: The SR OS ASBR does not currently support receiving a non-recursive opaque FEC (opaque type 1). |
The LEAF (PE-2) has to have the ROOT-1 system IP installed in RTM via BGP. If the ROOT-1 is installed in RTM via IGP, the LEAF will not generate the recursive opaque FEC. As such, the ASBR 3 will not process the LDP FEC correctly.
3.4.16.5.2. Configuration Example
No configuration is required for Option B or Option C on ASBRs, although for Option B, config>router>bgp>enable-inter-as-vpn is required to enable inter-as-non-segmented MLDP through the ASBR router.
Policy is required for a root or leaf PE for removing the NO_EXPORT community from MVPN routes, which can be configured using an export policy on the PE.
The following is an example for configuring a policy on PEs to remove the no-export:
The following is an example for configuring in BGP the policy in a global, group, or peer context:
3.4.16.5.3. Inter-AS Non-segmented MLDP
Refer to the “Inter-AS Non-segmented MLDP” section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide for more information.
3.4.16.5.4. ECMP
Refer to the “ECMP” section of the 7450 ESS, 7750 SR, 7950 XRS, and VSR MPLS Guide for more information about ECMP.
3.4.17. Weighted ECMP and ECMP for VPRN IPv4 and IPv6 over MPLS LSPs
ECMP over MPLS LSPs for VPRN services refers to spraying packets across multiple named RSVP and SR-TE LSPs within the same ECMP set.
The ECMP-like spraying consists of hashing the relevant fields in the header of a labeled packet and selecting the next-hop tunnel based on the modulo operation of the output of the hash and the number of ECMP tunnels. The maximum number of ECMP tunnels selected from the TTM matches the value of the user-configured ecmp option. Only LSPs with the same lowest LSP metric can be part of the ECMP set. If the number of these LSPs is higher than the value configured in the ecmp option, the LSPs with the lowest tunnel IDs are selected first.
In weighted ECMP, the load-balancing weight of the LSP is normalized by the system and then used to bias the amount of traffic forwarded over each LSP. The weight of the LSP is configured using the config>router>mpls>lsp>load-balancing-weight weight and config>router>mpls>lsp-template>load-balancing-weight weight commands.
If one or more LSPs in the ECMP set have no load-balancing-weight configured, and the ECMP is set to a specific next hop, regular ECMP spraying is used.
Weighted ECMP is configured for VPRN services with SDP auto-bind by using the config>service>vprn>auto-bind-tunnel>ecmp max-ecmp-routes and config>service>vprn>auto-bind-tunnel>weighted-ecmp commands. Weighted ECMP is disabled by default.
The ecmp max-ecmp-routes command allows explicit configuration of the number of tunnels that auto-bind-tunnel can use to resolve for a VPRN. The max-ecmp-routes parameter range is 0 to 32.
If weighted ECMP is enabled, then a path is selected based on the output of the hashing algorithm. Packet paths are then mapped to LSPs in the SDP in proportion to the configured load-balancing weight of the LSP. The hash is based on the system load-balancing configuration.
3.5. FIB Prioritization
The RIB processing of specific routes can be prioritized through the use of the rib-priority command. This command allows specific routes to be prioritized through the protocol processing so that updates are propagated to the FIB as quickly as possible.
The rib-priority command can be configured within the VPRN instance of the OSPF or IS-IS routing protocols. For OSPF, a prefix list can be specified that identifies which route prefixes should be considered high priority. If the rib-priority high command is configured under an VPRN>OSPF>area>interface context then all routes learned through that interface is considered high priority. For the IS-IS routing protocol, RIB prioritization can be either specified though a prefix-list or an IS-IS tag value. If a prefix list is specified than route prefixes matching any of the prefix list criteria will be considered high priority. If instead an IS-IS tag value is specified then any IS-IS route with that tag value will be considered high priority.
The routes that have been designated as high priority will be the first routes processed and then passed to the FIB update process so that the forwarding engine can be updated. All known high priority routes should be processed before the routing protocol moves on to other standard priority routes. This feature will have the most impact when there are a large number of routes being learned through the routing protocols.